Cvičení 9
Shlukování k-means
Vojtěch Franc
Cílem tohoto cvičení je implementace algoritmu k-means pro shlukovou analýzu
dat. Algoritmus 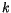 -means iterativně hledá hodnoty
-means iterativně hledá hodnoty 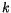 vektorů
vektorů
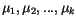 tak, že minimalizuje střední odchylku mezi zadanou množinou dat
tak, že minimalizuje střední odchylku mezi zadanou množinou dat
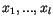 ,
, 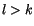 a vektory
a vektory 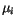 , které mají k těmto datům nejmenší
euklidovskou vzdálenost. Neformálně řečeno
, které mají k těmto datům nejmenší
euklidovskou vzdálenost. Neformálně řečeno 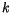 -means algoritmus aproximuje
množinu dat
-means algoritmus aproximuje
množinu dat 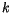 vhodně zvolenými vektory.
vhodně zvolenými vektory.
K-means
Algoritmus 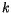 -means je skutečně jednoduchý. Jeho vstupem je množina dat
-means je skutečně jednoduchý. Jeho vstupem je množina dat
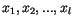 a číslo
a číslo 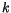 udávající počet vektorů
udávající počet vektorů 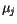 ,
, 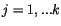 .
Na začátku se inicializují vektory
.
Na začátku se inicializují vektory 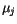 ,
, 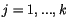 na náhodně zvolenou
hodnotu nebo použitím nějaké vhodně zvolené heuristiky (např. využívající
apriorní znalost o úloze). Po inicializaci se začnou iterativně opakovat
následující dva kroky:
na náhodně zvolenou
hodnotu nebo použitím nějaké vhodně zvolené heuristiky (např. využívající
apriorní znalost o úloze). Po inicializaci se začnou iterativně opakovat
následující dva kroky:
- Klasifikace: Všechna data
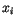 ,
, 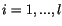 se klasifikují do tříd
určených vektry
se klasifikují do tříd
určených vektry 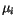 ,
, 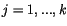 podle minima euklidovské
vzdálenosti. Tedy vzor
podle minima euklidovské
vzdálenosti. Tedy vzor 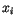 je přiřazen do třídy
je přiřazen do třídy 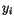 podle
podle
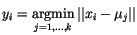 .
.
- Přepočítání vektorů
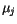 : Vypočítají se nové hodnoty vektorů
: Vypočítají se nové hodnoty vektorů
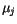 jako střední hodnoty dat
jako střední hodnoty dat 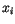 , které byly klasifikovány do třídy
určené příslušným vektorem
, které byly klasifikovány do třídy
určené příslušným vektorem 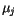 . Tedy nová hodnota
. Tedy nová hodnota 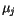 se spočte
podle ztahu
se spočte
podle ztahu
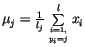 ,
kde
,
kde 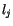 je poče vzorů
je poče vzorů 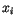 klasifikovaných v druhém kroku do třídy určené
vektorem
klasifikovaných v druhém kroku do třídy určené
vektorem 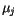 .
.
Kroky 1 a 2 se opakují do té doby dokud se alespoň jeden vektor 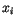 klasifikuje do jiné třídy než byl klasifikován v předcházejícím kroku.
Postupujte podle následujících bodů:
klasifikuje do jiné třídy než byl klasifikován v předcházejícím kroku.
Postupujte podle následujících bodů:
- Seznamte se algoritmem
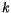 -means popsaném v odstavci 2
a implementujte ho.
-means popsaném v odstavci 2
a implementujte ho.
- Vygenerujte si datové množiny obsahující několik dobře
oddělitelných shluků. Použijte program
creatset ze Statistical Pattern Recognition
Toolboxu.
- Aplikujte algoritmus
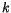 -means na vygenerovaná data a výsledek,
tj. klasifikování dat do shluků, si zobrazte pomocí funkce
ppatterns.
-means na vygenerovaná data a výsledek,
tj. klasifikování dat do shluků, si zobrazte pomocí funkce
ppatterns.
Vojtech Franc
2001-12-05