Learning CNNs from Weakly annotated facial images
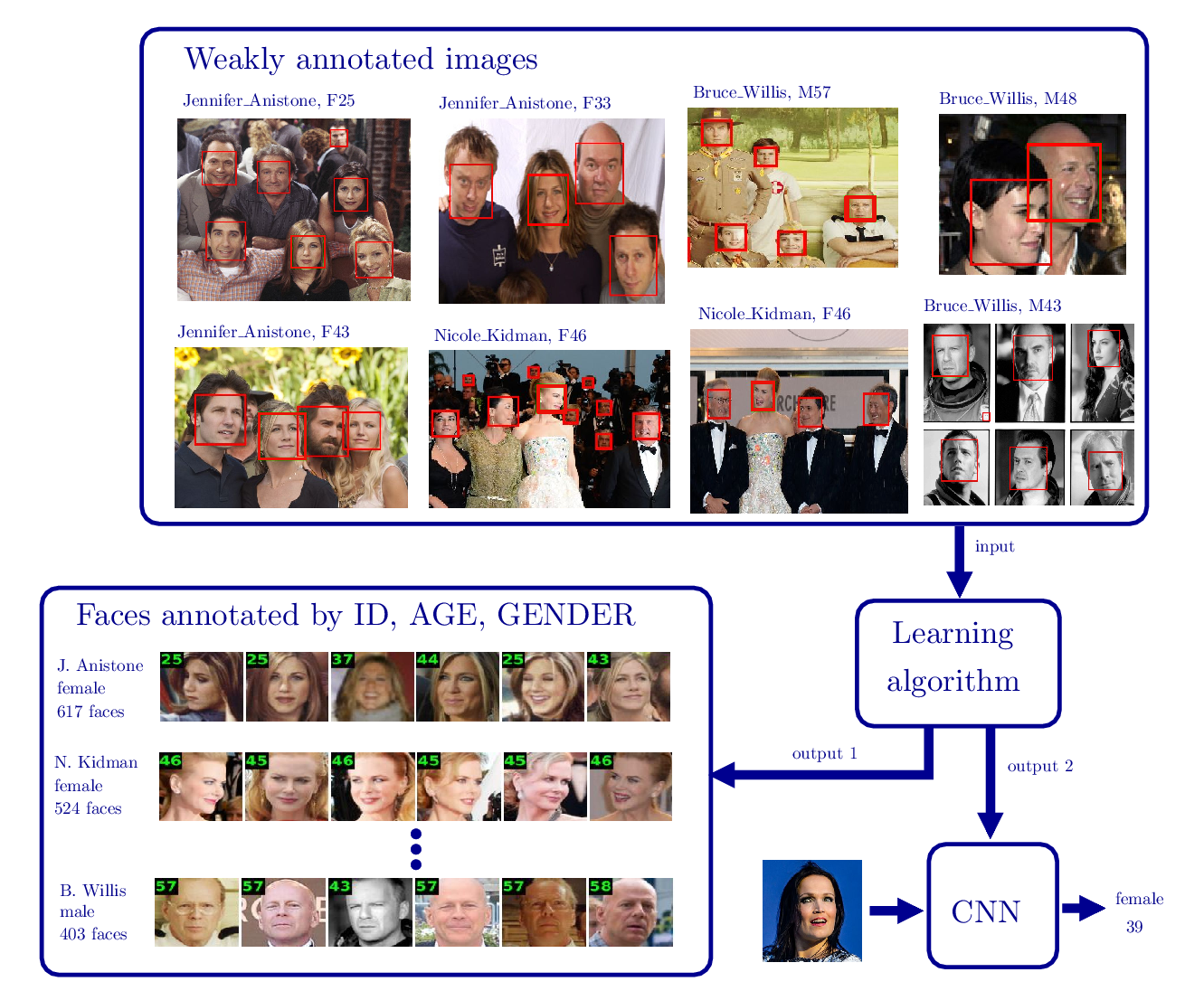
We consider learning of CNN for prediction of biological age and gender from facial images. We propose a semi-supervised learning algorithm, named EM-CNN, which uses only weakly annotated data. The weakly annotated data can be collected by an automated process producing images each annotated by age, gender and identity of a person captured in the image. However, each image can contain multiple faces, automatically found by a face detector, and the challenge is to link the annotation with a the correct face. Besides the CNN predicting age and gender our learning algorithm also provides the missing link between the weak annotation and the faces, so it produces fully annotated facial examples that can be used in supervised methods.
Results
We apply the EM-CNN to weakly annotated images from IMDB database. The IMDB database is composed of 460k images of celebrities containing 860k faces (we used a commercial face detector).
A sample of full annotation created by the EM-CNN can be seen here ( click on faces to see the original IMDB image ).
The IMDB database is among the largest public databases for age/gender prediction. [Rothe2015] proposed a heuristic method to link the annotation to the detected faces. This annotation is currently used by many state-of-the-art methods. The table below compares the number of annotated faces and the accuracy of the annotation (portion of correctly annotated faces among those which were selected by the method) obtained by i) the heuristic method of Rothe and ii) by the proposed EM-CNN:

Below is comparison of the prediction accuracy of a CNN trained by i) supervised learning using the heuristically annotated examples and ii) by the proposed EM-CNN algorithm:

Download
We provide the annotation of IMDB dataset created by the EM-CNN. Each face is describe by its bounding box, celebrity name, biological age and gender.
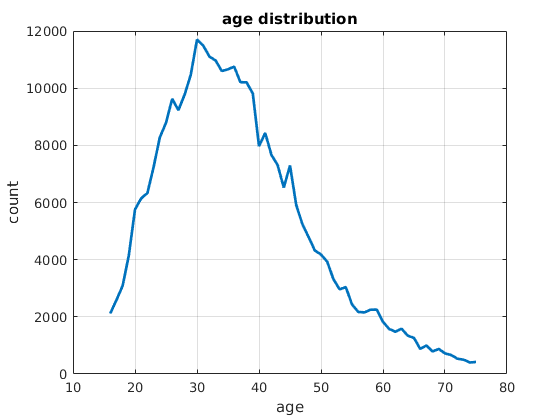
- number of faces: 311,085 (male=177,170 / female=133,915)
- number of identities: 8,925
- annotation in TXT file: emcnn_annotion_18-Nov-2017.txt
The text file contains the following tabulator separated values:
imdb_image_path celebrity_name bbox_left bbox_top bbox_right bbox_bottom age gender score
imdb_image_pathimage path inside IMDB database. The IMDB images can be downloaded here.- [
bbox_leftbbox_topbbox_rightbbox_bottom] rectangular bounding box found by a commercial face detector. scoreis the probability that the annotation is correct. To get annotation with a higher precision discard faces with lower score.