Bayesovská úloha rozhodování
Cílem tohoto cvičení je vytvořit bayesovský klasifikátor pro dvě třídy s 0-1 (nula-jedna)
ztrátovou funkcí.
Formulace úlohy
Navrhněte klasifikátor, který bude rozpoznávat dva typy písmen K = {"A","C"} a
to pouze na základě následujího jednoho měření
x = (součet hodnot pixelů v levé polovině obrázku) - (součet hodnot
pixelů v pravé polovině obrázku)
Toto měření (tzv. příznak) tedy přiřazuje každému obrázku jedno reálné číslo.
Budeme předpokládat, že známe relativní četnost písmen "A" a "C" v dané obrazové
sadě, tj. známe apriorní pravděpodobnosti p(A) a p(C). Dále předpokládejme, že
známe podmíněné pravděpodobnost p(x|A) a p(x|C), tj. pravděpodobnost naměření
hodnoty x mezi písmeny A a C. Pravděpodobnosti p(x|A) a p(x|C) budou
Gaussovská rozdělení zadaná střední hodnotou a směrodatnou odchylkou. Cílem je
navrhnout bayesovský klasifikátor (strategii), tj. funkci k=q(x) minimalizující
bayesovské riziko.
Náš případ je jednoduší než obecná úloha nalezení bayesovské strategie v tom,
že množina rozhodnutí D je rovna množině vnitřních stavů K a že ztrátová funkce
W nabývá pouze hodnot 0 (pro správné rozhodnutí) a 1 (pro chybné rozhodnutí). V
tomto speciálním případě je klasifikátor q dán vztahem (viz přednáška o
bayesovském rozhodování, slajdy 22-23)
q(x) = argmax_k p(k|x) = argmax_k p(k,x)/p(x) = argmax_k p(k,x) =
argmax_k p(k) p(x|k)
kde p(k|x) se označuje jako aposteriorní pravděpodobnost třídy k za
předpokladu měření x. Symbol argmax_k znamená nalezení takového k, pro které je
argument největší.
Připomínáme, že vzoreček pro hustotu Gaussovského (tj. normálního) rozdělení
jedné proměnné je
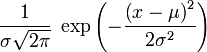
kde μ je střední hodnota a σ je směrodatná odchylka (rovná odmocnině z
variance neboli rozptylu).
Zadání
Poznámka: Doporučujeme vypracovat body 1
a 4 již před cvičením.
- Ukažte, že pro dvě třídy a za předpokladu, že p(x|A) a p(x|C) jsou
Gaussovská rozdělení, je diskriminační funkce bayesovské strategie
kvadratická. Odvoďte vztahy pro koeficienty této kvadratické fce.
Nápověda: Máme-li jen dvě třídy, diskriminační funkce je taková
funkce, která když je kladná tak klasifikujeme do první třídy a v opačném
případě do druhé. Pro výše uvedený klasifikátor q(x) to znamená (odvoďte),
že se rozhodneme pro třídu "A" právě když
p(A) p(x|A) - p(C) p(x|C) >= 0
Dosadíme-li za p(x|A) a p(x|C) příslušná Gaussovská rozdělení a celou
nerovnici zlogaritmujeme, získáme kvadratickou nerovnici vzhledem k
x.
- Stáhněte si a nahrajte do Matlabu datový soubor data_33rpz_cv02.mat
obsahující obrázky, apriorní pravděpodobnosti p(A) a p(C) a parametry
rozdělení p(x|A) a p(x|C).
Popis dat:
| images |
- |
10x10x160, pole 160 obrázků
10x10 s písmeny "A" a "C" |
| D1 |
- |
struktura s parametry
distribuce p(x|A) = N(D1.Mean,
D1.Sigma) |
| D1.Mean |
- |
střední hodnota p(x|A) |
| D1.Sigma |
- |
směrodatná odchylka p(x|A) |
| D1.Prior |
- |
pravděpodobnost p(A), tj.
četnost písmen A v datové sadě |
| D2 |
- |
struktura s parametry
distribuce p(x|C) = N(D2.Mean,
D2.Sigma) |
| D2.Mean |
- |
střední hodnota p(x|C) |
| D2.Sigma |
- |
směrodatná odchylka p(x|C) |
| D2.Prior |
- |
pravděpodobnost p(C), tj.
četnost písmen C v datové sadě |
| labels |
- |
1x160, vektor se správnou
klasifikací (použijete pouze pro výpočet chyby) |
| Alphabet |
- |
1x2, Alphabet = 'AC',
abeceda |
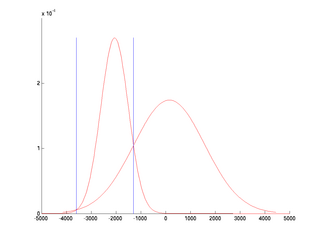
- Vykreslete normované histogramy příznaku x na třídách A a C a
klasifikační prahy. (Použijte funkce hist a
bar). Histogramy normujte tak, aby jejich
plocha byla rovna 1 (tj. aby šlo o distribuci).
Nápověda:
[N, u] = hist(x);
N = N / ( sum(N)*(u(2)-u(1)) ); % normalizace
bar(u,N);
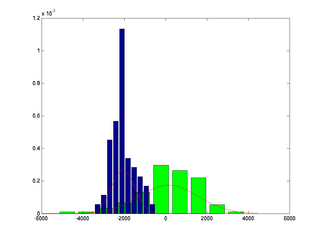
- Pro uvedená data vyčíslete koeficienty kvadratické diskriminační funkce
a klasifikujte obrázky do jednotlivých tříd. Výsledek zobrazte (například
zobrazte všechny obrázky klasifikované jako A a obrázky klasifikované jako
C).
- Určete hodnoty klasifikačních prahů t1 a t2
takových, že kvadratická nerovnice a*x2 + b*x +c >= 0 se nahradí
dvěma nerovnicemi x≥t1 a x≤t2 pokud a<0 .
- Pomocí funkce pgmm z toolboxu
stprtool zobrazte do jednoho obrázku hustoty
pravděpodobností a klasifikační prahy t1, t2. Můžete
je nakreslit přes histogramy z bodu 3 nebo do samostatného obrázku.
- Vytvořte funkci
[risk,epsA,epsC,interA]
= bayeserror(D1,D2) vracející bayesovský risk a klasifikační prahy.
Vstupem funkce budou struktury D1 a D2 obsahující parametry distribucí p(x|A),
p(x|C) a apriorní pravděpodobnosti tříd p(A), p(C) (viz bod 2). Výstupem
bude:
| risk |
- |
risk/chyba optimální
bayesovské strategie |
| epsA |
- |
integrál p(x|A) přes x z LC,
kde LC je oblast, ve které je x klasifikováno do třídy C.
|
| epsC |
- |
integrál p(x|C) přes x z LA,
kde LA je oblast, ve které je x klasifikováno do třídy A.
|
| interA |
- |
jeden nebo dva intervaly
popisující oblast LA |
Nápověda: Pro vyčíslení integrálů exponenciál použijte funkci
erfc2,
která je součástí toolboxu stprtool.
- Pomocí správné klasifikace obrázků uvedené ve vektoru
labels spočtěte skutečnou chybu klasifikace
na třídě "A" a "C" a celkovou chybu (porovnejte s výstupem funkce
bayeserror).
V případě nejasností zadání kontaktujte cvičící.
Bonusová úloha
Tato úloha není povinná. Jejím
vypracováním vám dáváme možnost proniknout do problematiky hlouběji. A
samozřejmě, po odevzdání vypracované bonusové úlohy získáváte bonusový bod,
který se počítá v závěrečném hodnocení.
Všechna potřebná data naleznete v souboru
data_33rpz_cv02_bonus.mat. Příklad je podobný předchozímu, pouze jsme
rozšířili počet příznaků a počet tříd. Namísto jednoho příznaku budeme nyní
používat dva. Jako druhý příznak použijeme
y = (součet hodnot pixelů v horní
polovině obrázku) - (součet hodnot pixelů v
dolní polovině obrázku)
Počet tříd (délku abecedy) jsme rozšířili ze dvou písmen na tři ("A", "C",
"T").
Cílem je klasifikovat pomocí optimální bayesovské strategie tři typy písmen a to
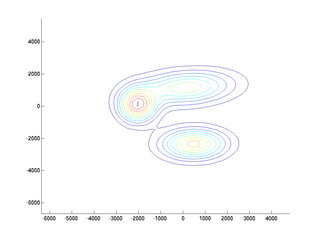
pomocí zmíněných dvou jednoduchých příznaků. Pro představu problém vypadá asi
takto (získáno pomocí funkce pgmm)
Výstupy:
- Chyba klasifikace na testovací množině
- Vizualizace klasifikace na obrázcích písmen (které bylo kam
klasifikováno)
Nápověda:
- Hustota Gaussovského rozdělení více proměnných je dána vzorečkem
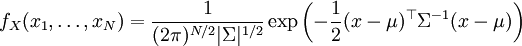
kde μ je (sloupcový) vektor středních hodnot, Σ je kovarianční matice
(zobecnění variance), a |.| značí determinant. Kovarianční matici máte v
nahraných datech. Na vyčíslení tohoto vzorečku můžete použít funkci
pdfgauss,
ale více se naučíte pokud ji nepoužijete.
Doporučená literatura
Created by Martin
Urban, 5.10.2006, last update 10.03.2009