Hairstyle Transfer between Face Images
Faculty of Electrical Engineering, Czech Technical University in Prague

Abstract
We propose a neural network which takes two inputs, a hair image and a face image, and produces an output image having the hair of the hair image seamlessly merged with the inner face of the face image. Our architecture consists of neural networks mapping the input images into a latent code of a pretrained StyleGAN2 which generates the output high-definition image. We propose an algorithm for training parameters of the architecture solely from synthetic images generated by the StyleGAN2 itself without the need of any annotations or external dataset of hairstyle images. We empirically demonstrate the effectiveness of our method in applications including hair-style transfer, hair generation for 3D morphable models, and hair-style interpolation. Fidelity of the generated images is verified by a user study and by a novel hairstyle metric proposed in the paper.
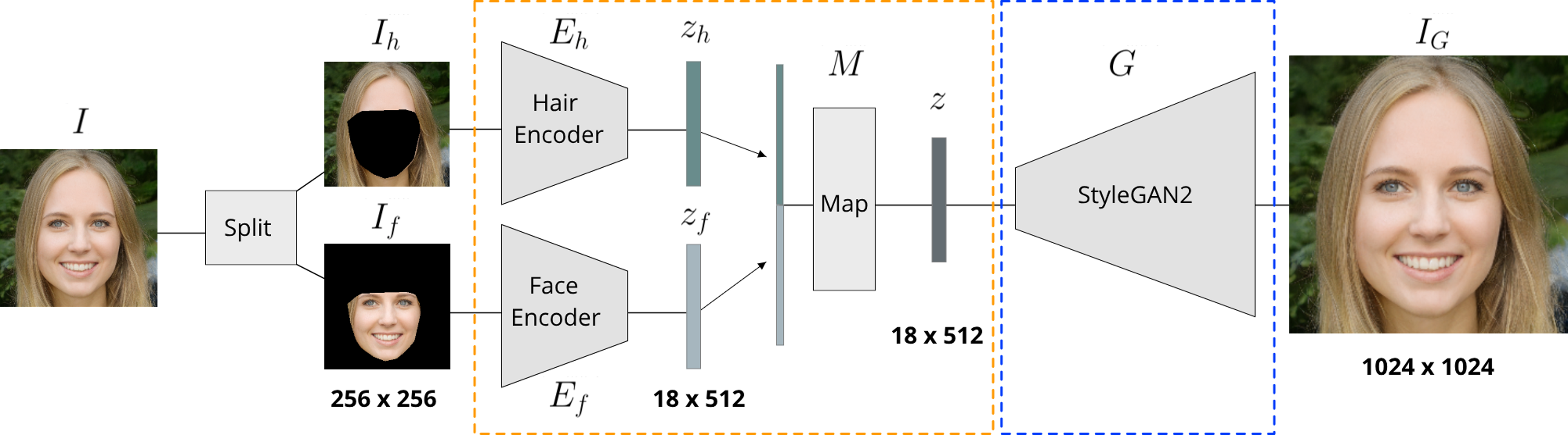
Architecture
Input image is split into inner face (If) and hair (Ih) images. The separating mask is constructed from facial landmarks. Both parts are encoded independently into embeddings of dimension 18 x 512. The two embeddings are concatenated and mapped into a code from StyleGAN latent space (W+). This code is subsequently transformed into the final image via StyleGAN. During training we only update the parameters in the orange box.
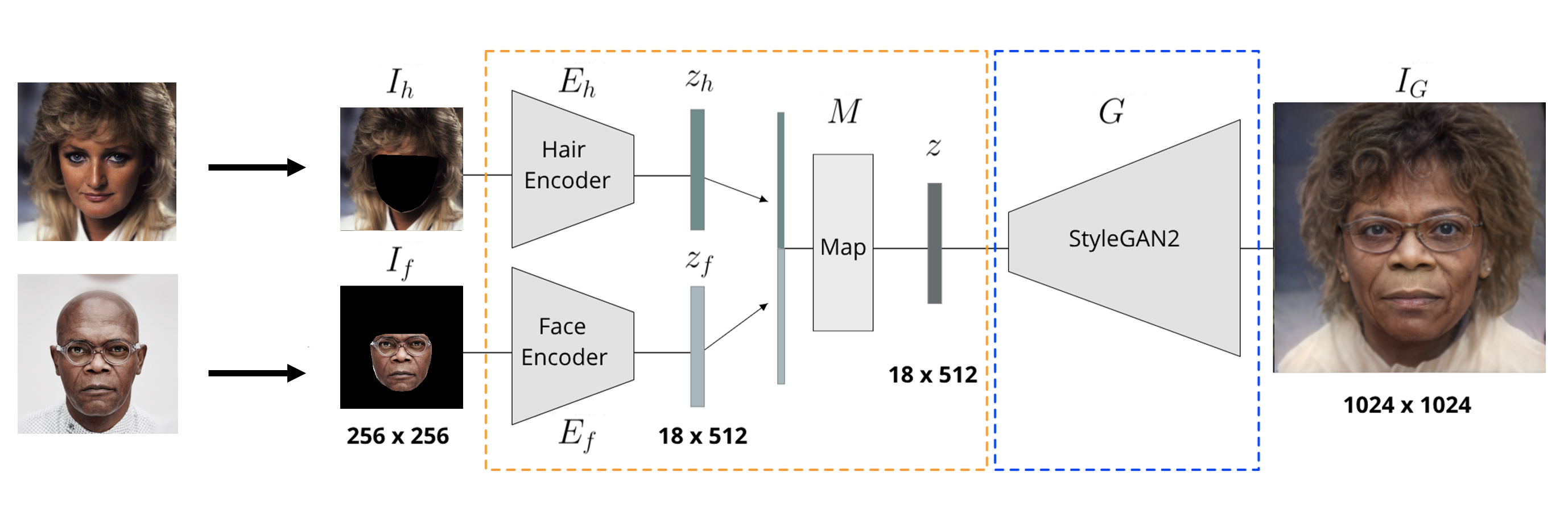
Hairstyle Transfer
Hairstyle Transfer is achieved by matching hair and face inputs from different images (as shown in the figure).
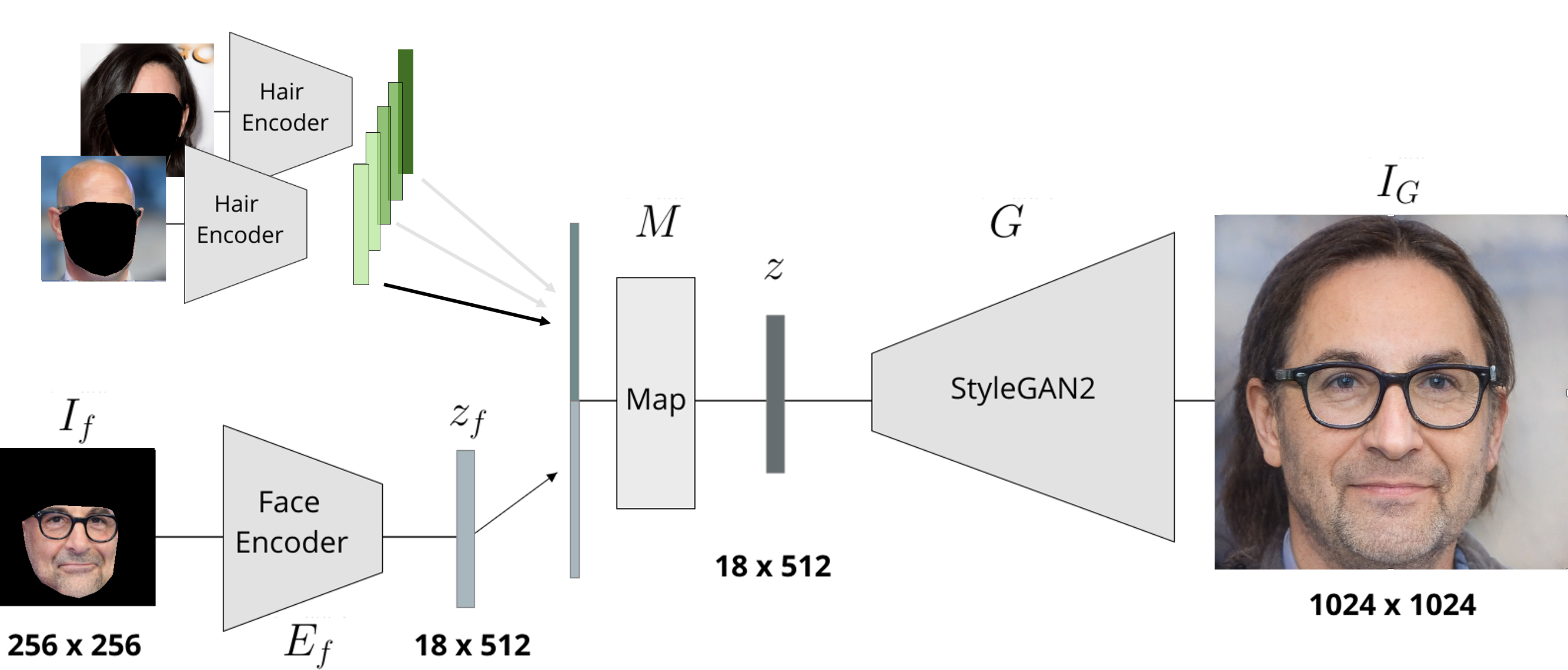
Hairstyle Interpolation
Hair embeddings are obtained for two input images and several convex combinations of those embeddings are generated (green). The face emedding is the same for every convex combination.
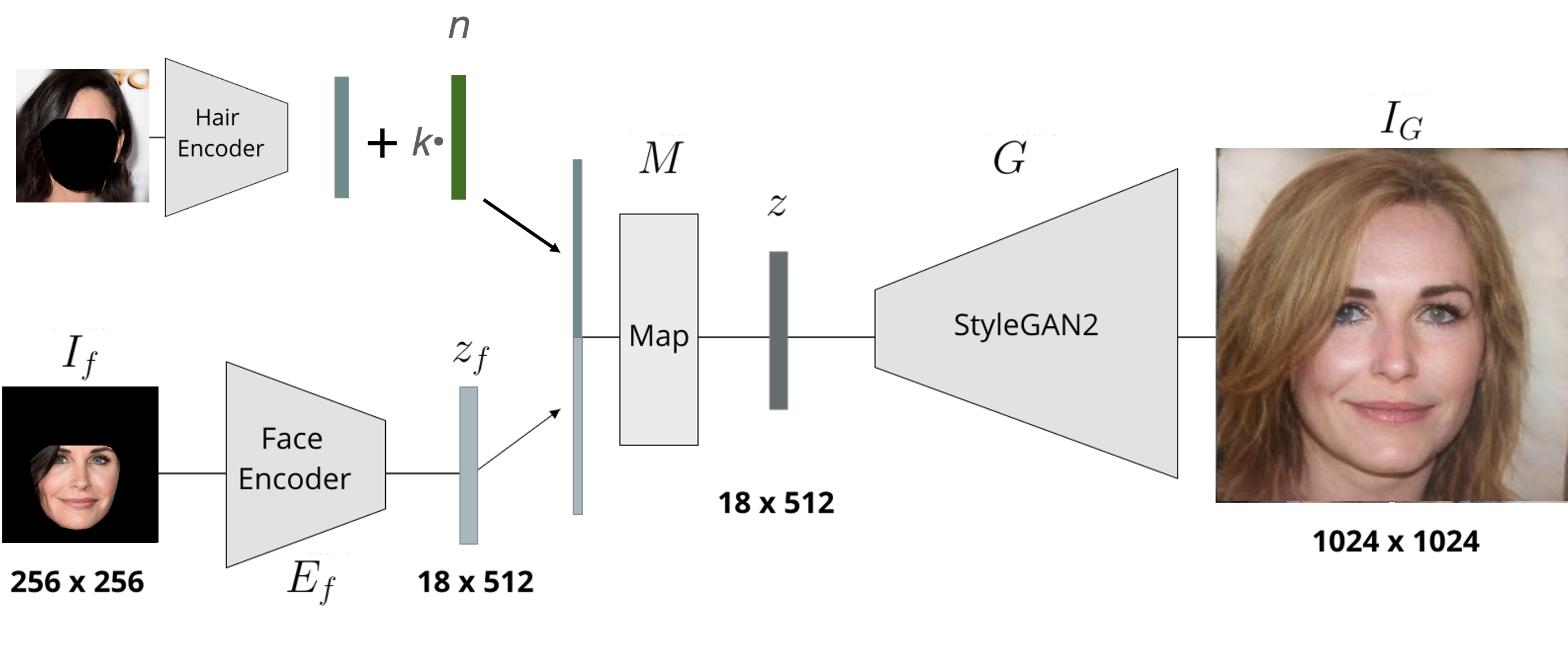
Hairstyle Manipulation
Latent space editing in the space of hair emeddings. Vector n represents some meaningful direction in the latent space ( hair color/structure change). Scalar k is the strength of the edit.