Popis mikrokontroléru MC68332
a vyuľití GNU vývojového prostředí systému Linux
Pavel Píąa ( pisa@cmp.felk.cvut.cz )
1 Popis mikrokontroléru
Obvod MC683321 je 32 bitový vysoce integrovaný mikrokontrolér, který kombinuje výkonné jádro
s rozsáhlým vstupně výstupním subsystémem. Jednotlivé moduly jsou propojeny
vnitřní sběrnicí. Základním modulem je 32 bitová CPU (CPU32 [2]) odvozená
z řady procesorů 68000, jedná se o modifikovanou verzi 68020.
Daląí moduly jsou
- system integration module (SIM) modul vnitřního a vnějąího propojení
- time processor unit (TPU) výkonný časovací kontrolér
- queued serial module (QSM) sériová rozhraní
- 2-Kbyte TPU SRAM module (TPURAM) pamě» pouľitelná pro hlavní procesor nebo pro
uľivatelský mikrokód pro TPU
Zdroj hodinového signálu můľe být buď vnějąí signál s úrovněmi TTL nebo interní
násobička s fázovým závěsem s referenčním krystalem 32.768-kHz. Ve druhém případě
je moľné měnit frekvenci procesoru i za běhu pouze změnou poľadovaného poměru
vnitřního a referenčního hodinového signálu.
Spotřeba je vzhledem k pouľité technologii HCMOS velmi malá a statická architektura
registrů a paměti umoľňuje její sníľení na minimum při zastavení systémových
hodin instrukcí low-power stop (LPSTOP). Okamľitý stav registrů a paměti zůstane
zachován do příchodu některé z očekávaných událostí.
1.1 Přehled vlastností jednotlivých modulů
-
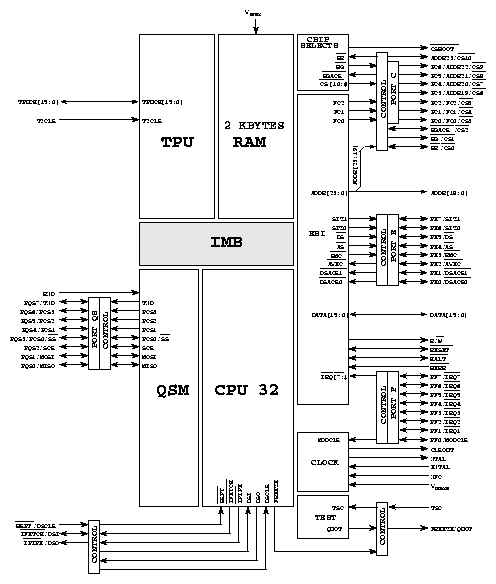
Figure 1: Funkční bloky 68332
- System Integration Module (SIM)
-
- Obstarává propojení vnitřní ( mezimodulové ) a externí sběrnice
- Obsahuje logiku programovatelných chipselectů
- Umoľňuje ochranu systému
- Obsahuje kontrolní čítač watchdog, hlídání správné hodinové frekvence,
monitor systémové sběrnice
- Systémové hodiny mohou být odvozeny od 32.768-kHz krystalu, výsledkem je pak
nízká spotřeba
- Obsahuje testovací/ladící logiku pro výrobní a uľivatelské testování a
pro vývoj
- Central Processing Unit (CPU)
-
- Strojový kód shora kompatabilní s procesory MC68000 a MC68010
- Nové instrukce pro řídící aplikace
- 32-bitová architektura
- Umoľňuje ve spolupráci s vnějąí MMU ( Memory Management Unit ) implementovat
virtuální pamě»
- Rychlé provádění cyklů obsahujících jednu instrukci
- Instrukce pro práci a interpolaci tabulek
- Vylepąené zpracování vyjímek pro řídící aplikace
- Podporuje trasování do změny toku instrukcí ( návrat, volání, ... )
- Obsahuje vstup pro vnějąí signál hardwarového breakpointu a kompletní logiku
pro ladění Background Debug Mode
- Plně statická činnost umoľňuje sniľování a i zastavení hodin procesoru
- Time Processor Unit (TPU)
-
- Obsahuje vlasní řadič mikrokódu pracující nezávisle na CPU32
- 16 nezávislých, programovatelných kanálů a pinů
- Kaľdý kanál můľe vykonávat libovolnou časovou funkci
- Více kanálů můľe být vzájemně synchronizováno nebo můľe vytvářet sloľitějąí
funkci vyuľívající více pinů
- Dva čítače času s programovatelnými předděličkami
- Volitelnou prioritu jednotlivých kanálů
- Queued Serial Module (QSM)
-
- Obsahuje sériový interface (SCI), univerzální asynchronní vysílač a přijímač
(UART) s volitelným módem, rychlostí a paritou
- Sériový interface pro připojení periferií s 80-Byte RAM, který umí provádět
aľ 16 přenosů automaticky
- Vstupy/výstupy s dvojí funkcí
- Cyklický mód, 8 aľ 16 bitů na jeden přenos
- Static RAM Module
- s moľností vyuľití pro emulaci TPU (TPURAM)
- 2-Kbyte statické paměti RAM
- Můľe být vyuľita jako normální rychlá RAM nebo pro emulaci mikrokódu TPU
1.2 Stručný popis CPU32
Procesor je zaloľen na architektuře CISC ( Complex Instruction Set Computer ).
Jádro procesoru je plně 32 bitové, vnějąí datová sběrnice je pouze 16 bitová.
Navenek je přístupných také pouze 24 adresových linek ( moľnost adresovat 16 MB
paměti ). Adresový prostor je lineární, bez jakýchkoli omezení a segmentací,
pro periferie není vyhrazen speciální prostor. Systémová pamě» ( včetně boot
ROM ) i periferie mohou být organizovány 8 i 16 bitově. Pro 16 i 32 bitové přístupy
do paměti platí, ľe adresa musí být sudá. Veąkeré instrukce jsou 16 bitové s
moľností roząíření o daląí 16 bitová slova. Instrukce a zásobník musí být také
zarovnány na sudé adresy.
1.2.1 Registry a reľimy procesoru
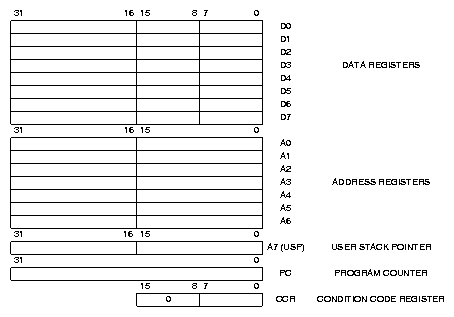
Figure 2: Uľivatelský model CPU32
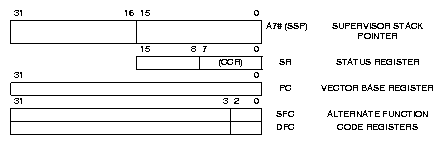
Figure 3: Systémový model CPU32
16 třicetidvou bitových registrů je rozděleno na 8 datových (D0-D7) a 8 adresových
(A0-A7). Datové registry lze pouľít pro operace s 32, 16 a 8 bity. Adresové
registry umoľňují pouze 32 bitové a 16 bitové operace a jsou-li pouľity jako
cíl 16 bitové operace je hodnota automaticky znaménkově roząířena na 32 bitů.
Datové registry lze pouľít k přístupu pouze v kombinaci s adresovým registrem
jako index. Adresové registry lze pouľít jako index i jako zdroj báze adresy.
Jediný z těchto registrů, který má speciální určení, je registr A7, který slouľí
jako ukazatel zásobníku. Tento registr je zdvojen, A7 (USP) ukazuje do zásobníku
uľivatelského programu, A7' (SSP) je pouľit v systémovém reľimu ( supervisor ).
Jediný moľný přechod z uľivatelského do systémového reľimu je pomocí vyjímek
( softwarově vyvolané k tomu určenou instrukcí, vnějąí přeruąení a způsobené
chybami při provádění instrukcí - ochrana paměti, ilegální instrukce atd. ).
Kaľdé vyjímce je přiřazen jeden z 256 třicetidvoubitových vektorů uloľených
v paměti od adresy uloľené v registru VBR ( po startu procesoru obsahuje 0 ).
Vnějąí přeruąení mohou mít prioritu 0 aľ 7 ( priorita 0 sloľí k zakázání přeruąení )
a mohou v potvrzovacím cyklu předat hodnotu vektoru přeruąení.
Stavový registr procesoru CPU32 je rozdělen na dvě části, systémovou část a
podmínkový registr (CCR), který je přístupný i z uľivatelského reľimu. Nevyuľité
bity stavového registru jsou čteny jako 0 a měly by také být také tak zapisovány
pro zachování kompatability s novějąími procesory. Systémová část stavového
registru obsahuje dva bity pro řízení trasování (T1 a T0), příznak systémového
reľimu (S) a masku priority přeruąení (IP2 aľ IP0). Povolení trasování způsobí
po naplnění SR ze zásobníku a návratu instrukcí RTE do trasovaného programu
vyvolání vyjímky po provedení jedné instrukce. CPU32 umoľňuje i trasování, při
kterém dojde k vyjímce pouze při změně toku vykonávaných instrukcí ( například
skok, návrat, volání ). Maska přeruąení povoluje procesoru přijmout pouze vnějąí
poľadavky na přeruąení s vyąąí prioritou. Vyjímku představuje pouze vnějąí úroveň
7, která je pouľita pro nemaskovatelná přeruąení.
Bity podmínkové části (CCR) stavového registru jsou plněny logickými, aritmetickými
a bitovými operacemi a operacemi rotací a posunů. Příznak X slouľí k roząiřování
operací na operandy větąí délky neľ 32 bitů. Příznaky N a Z informuje o záporném/nulovém
výsledku předchozí operace. Indikace přetečení a přenosu jsou uloľeny do příznaků
V a C.
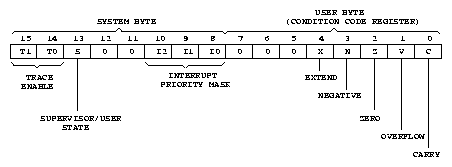
Figure 4: Stavový registr
Větąina kompilátorů vyuľívá registr A6 jako ukazatel na rámec zásobníku aktuální
funkce. Registr A5 bývá pouľit pro kód nezávislý na svém umístění - PIC ( Possition
Independent Code ). Registr D0 a pro 64 bitové výsledky i D1 větąinou slouľí
pro předání návratové hodnoty funkcí.
1.2.2 Adresace - konvence
Pro přístup k operandům slouľí 14 reľimů adresace. V literatuře je uľívána následující
konvence pro popis reľimů adresace a instrukcí.
- EA
- efektivní adresa
- An
- adresový registr n, například A3
- Dn
- datový registr n, například D3
- Rn
- libovolný z datových a adresových registrů
- Xn.SIZE*SCALE
- index registr, libovolný datový nebo adresový registr
- SIZE
- velikost indexu W ( 16 bitový ) nebo L ( 32 bitový )
- SCALE
- měřítko - násobitel indexu 1, 2, 4 nebo 8
- PC
- čítač programu
- SR
- stavový registr
- SP
- ukazatel zásobníku ( A7 - USR nebo SSR )
- CCR
- podmínkový registr, niľąí byte SR
- USP
- ukazatel zásobníku v uľivatelském reľimu
- SSP
- ukazatel zásobníku v systémovém reľimu
- dn
- ofset, délky n bitů
- bd
- báze adresy aľ 32 bitů
- L
- délka 32 bitů ( long-word )
- W
- délka 16 bitů ( word )
- B
- délka 8 bitů ( byte )
- (An)
- závorky určují adresaci obsaľenou hodnotou
1.2.3 Reľimy adresace
Následuje krátký výčet jednotlivých reľimů adresace CPU32
- Rn
- obsah datového nebo adresového registru
- (An)
- obsah paměti na adrese An
- (An)+
- obsah paměti na adrese An s následnou inkrementací registru
o hodnotu danou délkou operandu
- -(An)
- nejdříve dojde k dekrementaci registru o délku operandu a pak je registr
pouľit k adresaci
- (d16,An)
- adresový registr s 16 bitovým znaménkovým posunutím
- (d8,An,Xn)
- adresový registr s 8 bitovým znaménkovým posunutím a přičtením
indexového registru
- (bd,An,Xn*SCALE)
- adresa je vytvořena ze součtu adresového registru s indexovým
registrem násobeným měřítkem SCALE a bázovým posunutím délky aľ 32
bitů
- (xxx).W
- 16 bitová absolutní adresa
- (xxx).L
- 32 bitová absolutní adresa
- (d16,PC)
- adresace relativní k PC s ąestnáctibitovým znaménkovým posunutím
- (d8,PC,Xn)
- adresa relativní k PC s osmibitovým znaménkovým posunutím
a přičteným indexem
- (bd,PC,Xn*SCALE)
- adresa relativní k PC s posunutím aľ 32 bitů a
s indexem násobeným měřítkem
Pro úplnost jsou dále uvedeny i reľimy adresace, které nejsou implementovány
v jádře CPU32. Tyto reľimy jsou implementovány pouze v procesorech 68020 aľ
68060. Znalost těchto chybějících reľimů můľe být výhodná při hledání problémů
s programy původně určenými pro výkonnějąí členy rodiny 680x0.
- ([bd,An
- ,Xn,Od)]adresu tvoří hodnota v paměti na adrese An+bd,
ke které je přičteno posunutí a index
- ([bd,PC
- ,Xn,od)]totéľ ale relativně k PC
- ([bd,An,Xn
- ,Od)]adresu tvoří hodnota v paměti na adrese An+Xn+bd,
ke které je přičteno posunutí
- ([bd,PC,Xn
- ,od)]totéľ ale relativně k PC
1.2.4 Instrukční soubor
Procesor CPU32 rozeznává asi 60 instrukcí, které po doplnění reľimy adresace
vytvářejí více neľ 1000 uľitečných kombinací. Základní datové typy jsou bity,
byty, čísla BCD, 16 bitová slova a 32 bitová dlouhá slova. Instrukční soubor
obsahuje obvyklé aritmetické, logické, bitové, přesunové a řídící instrukce.
Ze zajímavých instrukcí procesoru CPU32 je moľno povaľovat instrukce pro
interpolaci hodnot v indexovaných tabulkách a roząíření instrukcí pro násobení
a dělení oproti procesoru 68010 o plně 32 bitové operandy a dokonce o moľnost
násobení dvou 32 bitových čísel s 64 bitovým výsledkem a dělení 64 bitového
čísla číslem 32 bitovým.
Podrobnějąí informace o instrukcích a architektuře CPU32 lze nalézt v [2].
1.2.5 Výkonnějąí následníci CPU32
Při výběru určité rodiny procesorů je nutné uvaľovat i o jejích předpokladech
budoucího vývoje nebo náhrady za výkonnějąí členy a zachování alespoň částečné
kompatability s jiľ pouľitými členy. Rodina procesorů 680x0 byla v minulosti
zaloľena velmi velkoryse, v instrukčním souboru bylo vyhrazeno místo pro nové
instrukce a adresní módy, procesor od začátku pracoval s 32 bitovou lineární
adresou atd. V současné době vąak byla výkonnostně architektura 680x0 překonána,
proto se ve výkonných pracovních stanicích, personálních počítačích více prosazují
jiné architektury ( od firmy Motorola předevąím PowerPC [5] ). Avąak
jednoduchost, elegance, snadná integrovatelnost více bloků na jeden čip a relativně
nízká spotřeba předurčuje architekturu 680x0 k řídícím aplikacím. Pro aplikace,
kde jiľ výkon CPU32 obsaľeného v 68332 nepostačuje, lze uvaľovat o přidání některého
z výkonnějąích procesorů ( 68040, 68060 ), pro který můľe být 68332 vstupně/výstupním
koprocesorem a nebo pouze vysoce integrovaným blokem periferií. Daląí alternativou
od firmy Motorola jsou mikrokontroléry zaloľené na procesoru PowerPC.
Vhodnost koncepce rodiny 680x0 pro řídící aplikace vedla výrobce k úvahám o
jejích daląích výkonnějąích nástupcích. Výsledkem jsou mikrokontroléry zaloľené
na procesorovém jádře ColdFire 52xx [4], jehoľ architektura je zaloľena
přepracované a odlehčené verzi ( pouze jedna pipeline ) procesoru 68060. Procesor
má přepracovaný instrukční soubor, který přímo odpovídá RISC jádru procesoru.
Výsledkem je procesor s výkonem ( aľ 50 MIPS @ 54 MHz ) srovnatelným
s 68040 nebo Intel 486.
Vąechny výąe uvaľované varianty a rodiny procesorů jsou podporovány kompilátorem
GCC, proto přechody mezi jednotlivými procesory na úrovni rutin v jazyce ``C''
nejsou přílią cenově a časově náročné. Větąím problémem jsou rozdíly v integrovaných
periferiích ( kromě kombinace 68060 a 68332 kde periferie zůstávají ) a v návrhu
nového hardware.
1.3 Integrační modul (SIM)
Konfigurační a ochranný blok řídí operační mód mikrokontroléru. Dále blok obsahuje
ochranu proti zablokování nebo selhání sběrnice a ochranu proti zablokování
software ( watchdog ). Zdroj systémových hodin generuje hodinový signál pro
SIM, ostatní moduly připojené k vnitřní mezimodulové sběrnici (IMB) a pro vnějąí
zařízení. Dále poskytuje generátor periodického přeruąení pro řídící a systémové
funkce.
Interface vnějąí sběrnice vykonává přenosy mezi vnitřní sběrnicí (IMB) a vnějąím
adresním prostorem. Blok chipselectů můľe dekódovat z poľadované adresy aľ 11
libovolně pouľitelných výběrových signálů a jeden signál pro zaváděcí kód a
případně i firmwarovou pamě» ( boot ROM ). Pro kaľdý chipselect je moľno zvolit
velikost dekódované oblasti ( pouľita jako maska adresy ), počáteční adresu,
druhy přístupu ( čtení, zápis, potvrzení přeruąení ) a datovou ąířku připojené
paměti nebo periferie ( byte, word, liché byte, sudé byte ).
Testovací blok obsahuje logiku pro testování mikrokontroléru při výrobě.
O konfiguraci některých parametrů SIM je potřeba rozhodnout dříve, neľ dojde
k načtení počáteční hodnoty PC a SSP z adresy 0 boot ROM. Tyto parametry jsou
řízeny hodnotami přečtenými z datové sběrnice v době aktivního signálu RESET.
1.4 Časovací koprocesor (TPU)
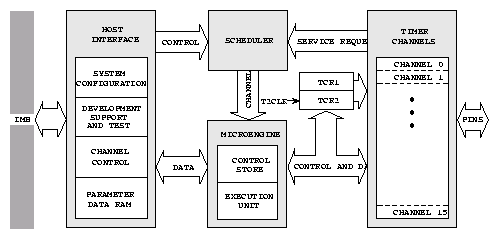
Figure 5: Časovací koprocesor TPU
Časovací koprocesor (TPU) umoľňuje řídit a zaznamenávat i relativně komplikované
časové děje. TPU obsahuje vlastní výkonnou jednotku, plánovač se třemi úrovněmi
priorit, dvoubránovou pamě» RAM pro zadávání konfigurace, příkazů a výměnu hodnot
s CPU32, dvě časové základny a pamě» ROM se standardními časovými funkcemi a
16 nezávislých kanálů. Funkce mohou být uľivatelem přeprogramovány za cenu vyuľití
interních 2KB paměti RAM pro uloľení mikrokódu TPU. Kaľdý kanál je propojen
s jedním vstupně výstupním pinem pro který je nezávisle definována časová funkce.
Více kanálů můľe být vzájemně propojeno a tvořit komplikovanějąí funkce ( například
fázový dekodér a čítač pro inkrementální čidla polohy, referenční a měřenou
frekvenci nebo sériové rozhraní ). Kaľdý kanál je doplněn hardwarem, který dovoluje
současné vstupní i výstupní události na vąech kanálech
1.5 Komunikační modul (QSPI)
Tento modul obsahuje podporu pro sériovou plně duplexní synchronní třídrátovou
sběrnici ( vodiče data in, data out a hodiny přenosu ). Čtyři piny pro výběrové
signály umoľňují připojit aľ 16 periferních zařízení. Vlasní RAM umoľňuje autonomní
provedení aľ 16 přenosů s délkou 8 aľ 16 bitů, nebo přenos bloku aľ 256 bitů.
Daląí moľností je periodický cyklický mód činnosti, který je vhodný pro automatické
obnovování čtených hodnot ( například pro roząíření systému o AD převodníky ).
Blok pro sériovou komunikaci (SCI) je určen pro obvyklou asynchronní sériovou
komunikaci. Přenáąená slova mohou být délky 8 nebo 9 bitů a mohou být doplněna
sudou nebo lichou paritou. Komunikace můľe být jak plně duplexní tak i poloduplexní
s přenosovou rychlostí 64 aľ 256 kbaud pro frekvenci systémového hodinového
signálu 16.78 MHz nebo 110 aľ 655 kbaud pro frekvenci 20.97 MHz. Přijímaný signál
je filtrován od ruąivých impulsů. Přijímač a vysílač jsou samostatně povolovatelné.
Oba jsou vybaveny dvojitým datovým registrem. Přijímač umoľňuje generování přeruąení
při příjmu dat s nastaveným devátým bitem, coľ je vhodné pro multiprocesorovou
komunikaci.
2 Přehled vývojových prostředků
Vývojové prostředky lze rozdělit do tří skupin. Hardwarové prostředky nutné
pro vývoj a oľivení vlastního procesorového systému. Prostředky pro vývoj aplikačního
programového vybavení. Systém umoľňující ladění takto vzniklých programů.
2.1 Hardwarové prostředky
Při ověřování návrhu hardware je často nutné testovat propojení a funkci základních
funkčních bloků nově navrhovaného systému. Hardwarová emulace nebo alespoň záznam
dějů v reálném čase jsou také nutné při ladění časově podmíněné obsluhy některých
periferií a při analýze odezvy systému na vnějąí události.
Klasický obvodový emulátor je externí zařízení, které se připojí místo procesoru
v cílovém zařízení. Emulátor větąinou obsahuje oddělovací logiku, řadič pomocných
sekvencí ( obvykle s pomocným procesorem ), interface pro komunikaci s nadřízeným
počítačem a náhradu cílového procesoru. Náhradou můľe být buď původní procesor
nebo speciální verze s vyvedenými vnitřními signály a nebo náhrada programovatelnými
obvody se shodnou funkcí. Protoľe se jedná o systémy vyráběné v malém počtu
je jejich cena vysoká.
Protoľe je integrace dneąních procesorových obvodů jiľ natolik vysoká a interní
mikrořadič dostatečně výkonný, je moľné přidat do mikroprogramů funkce umoľňující
při vývoji komunikovat přímo s jádrem mikroprocesoru. Takové řeąení sice mírně
zvyąuje sloľitost vyráběného obvodu, ale není pak nutné vyvíjet speciální emulační
verze ani relativně sloľitou logiku externího emulátoru. V případě mikrokontroléru
MC68332 je moľné vnějąími signály zastavit výkon instrukcí programu a začít
komunikovat s mikrořadičem přímo z nadřízeného počítače. Tento reľim je nazýván
BDM ( Background Debug Mode ). Mikrořadič dostává jednoduché příkazy třídrátovým
sériovým interfacem a informuje o výsledcích těchto příkazů stejnou cestou.
Na následujících obrázcích zobrazen klasický přístup s externím obvodovým
emulátorem (Obrázek 6) a systém vyuľívající interního emulátoru
procesoru MC68332 (Obrázek 7. Výhodou BDM je přítomnost hardwarové
emulace v kaľdé aplikaci a i na deskách, kde není mikrokontrolér umístěn v patici
( např. SMD verze mikrokontroléru ). Jistou nevýhodou proti některým externím
emulátorům je nemoľnost sledovat výkon instrukcí v reálném čase ( rychlost krokování
a emulace je dána předevąím rychlostí komunikace přes BDM interface ). Protoľe
je BDM sériová komunikace synchronizována hodinovým signálem ovládaným z nadřízeného
počítače, můľe být v mnoha případech rychlejąí, neľ komunikace s klasickým externím
emulátorem přes interface RS232.
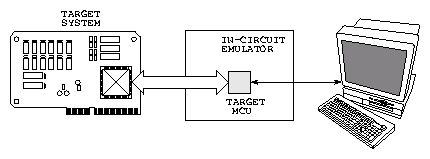
Figure 6:
Externí emulátor
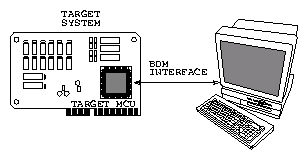
Figure 7:
Interní BDM emulátor
2.2 Prostředky pro vývoj software
Úkolem těchto nástrojů je převod popisu poľadované funkce do strojového kódu,
který je schopen cílový procesor vykonávat.
Ve větąině případů se jedná o překladače z vyąąí úrovně ( programovacího jazyka )
popisu do úrovně niľąí ( postupně jazyk symbolických adres - assembler a strojový
kód ). Dnes jiľ existují i prostředky pro převod popisu z blokových diagramů,
překladače z matematických a simulačních jazyků ( např. ze skriptů MatLabu nebo
z schémat nakreslených v Simulinku ). Pro lepąí přenositelnost mezi různými
cílovými architekturami je vąak větąina nástrojů stavěna hierarchicky. Postupný
překlad i u nejmodernějąích návrhových sytémů větąinou vyuľívá jiľ zavedené
standardní jazyky pouľívané na větąině platforem. Těmi je jazyk ``C'' popřípadě
``C++''. Pro kaľdou cílovou platformu je tedy nutné vytvořit překladače z
jazyka ``C'' do assembleru a z assembleru do cílového strojového kódu. Nejdůleľitějąím
článkem řetězce je kvalita překladače jazyka ``C'', jehoľ schopnost optimalizace
rozhoduje o délce a rychlosti výsledného kódu. Větąinou jedinou jinou cestou
jak zrychlit cílový kód je psaní některých částí přímo v assembleru.
Jinou alternativou je vyuľití cílového procesoru jako interpretru jiného popisu
poľadované funkce. Toto řeąení vąak vyľaduje výąe zmíněné prostředky alespoň
k vytvoření interpretru. Výsledná rychlost systému je negativně ovlivněna
spotřebováním části výkonu procesoru na analýzu popisu funkce.
2.3 Ladění aplikací
Posledními, ne vąak zanedbatelnými pomocníky při vývoji mikroprocesorového
systému nebo při tvorbě aplikací, jsou prostředky pro kontrolu, hledání zdrojů
chyb a rychlostního profilování aplikací. Pro počítače s obecným operačním systémem
a uľivatelským rozhraním ( terminálem ) se větąinou vyuľívá přímo vlastního
systému a pomocných programů na cílové platformě.
U systémů určených k řídícím aplikacím větąinou tento postup není moľný. Systém
má omezenou pamě», není vybaven terminálem, neumí zaručit současný běh
laděné aplikace a kontrolního programu, není odolný proti chybám v laděné aplikaci.
Podobné problémy je nutné řeąit i při vývoji vlastního operačního systému
i u větąích systémů.
V těchto případech je moľné pouľít jedné ze dvou metod. První je vyuľití jiľ
zmíněných hardwarových vývojových prostředků a nadřízeného počítače, jehoľ software
umoľňuje interpretovat stav procesoru na vyąąí úrovni abstrakce. Tou je například
moľnost ladění na úrovni vyąąího programovacího jazyka ( tzv. source level debugging
- ladění na úrovni zdrojového kódu ). K tomu je nutné mít k dispozici zdrojové
texty programů, informace o korespondenci řádek zdrojového textu s výsledným
strojovým kódem, informace o okamľitém umístění lokálních a globálních proměnných
v paměti a o reprezentaci různých datových typů v paměti a registrech cílového
počítače.
3 GNU Tool Chain
Soubor programů pro vývoj aplikací, který vznikl v rámci projektu GNU. Obsahuje
kompilátory jazyka ``C'', ``C++'', Objective-C, Pascal, Fortran, assembler
a daląí vývojové prostředky, debuggery, profilery, knihovny funkcí, RT i obvyklé
operační systémy.
3.1 Projekt GNU a FSF Inc
GNU projekt se zabývá vývojem alternativních volně ąiřitelných programů předevąím
pro systémy UNIXového typu.
Hodně lidí asi slyąelo o GCC, GDB, GNU Emacs atd.
Málo kdo vąak asi zná historii tohoto obrovského díla velkého mnoľství nezávislých
programátorů z celého světa, které je schopné co se kvality týče konkurovat
i velkým komerčním firmám.
Vąe začalo dopisem odeslaným 27. září 1983 ve 12:35:59 Richardem Stallmanem
z MIT AI Lab v Cambridgi. Tento autor editoru Emacs a mnoha daląích interpretrů,
kompilátorů, grafických knihoven atd. v dopisu píąe, ľe se rozhodl vytvořit
alternativu komerčních implementací UNIXu. Jeho základní pravidlo vyľaduje:
``Pouľívám-li nějaký program, který se mi líbí, musím mít právo ho vylepąit
a poskytnout i ostatním, kterým se líbí``.
V současné době se o správu projektu GNU stará nezisková organizace
pro software v obecném zájmu Free Software Foundation, Inc s E-mail adresou
`gnu@prep.ai.mit.edu`.
Přesto, ľe se vlastní systém GNU přílią neroząířil, umoľnila existence
volně ąiřitelného programového vybavení vznik operačních systémů jako je FreeBSD,
Hurd a Linux. Veąkeré programy jsou napsány s maximální snahou o přenositelnost
ve zdrojové formě na větąinu UNIXových systémů včetně IBM OS/2 ( projekt EMX ).
Velké mnoľství je moľné provozovat i v relativně nekompatibilních prostředích
jako je DOS ( projekt DJGPP ) nebo Win 95 a Win NT ( projekt CygWin32 ).
V daląím výkladu bude postupně popsán způsob vystavění vývojového řetězce. Protoľe
vyąąí vrstvy jsou závislé na niľąích vrstvách, je nutné začít řetězec budovat
od překladače assembleru, linkeru a daląích utilit pracujících na úrovni relokovatelného
a absolutního strojového kódu ( souhrnně se nazývají BINUTILS - Binary Utilities ).
Poté je moľno přistoupit k přípravě překladače GCC jazyka ``C'', kompilaci
knihoven a vlastního operačního systému a aplikací. Nakonec bude popsána příprava
ladícího programu - debuggeru GDB.
3.2 Programy nutné pro přípravu vývojového prostředí
Následující nainstalované programy jsou nutné k přípravě GNU vývojového prostředí
kompilací ze zdrojových textů:
- make
- verze GNU programu make, který podle času modifikace jednotlivých souborů
a databáze moľných způsobů jejich překladu rozhoduje o tom, které soubory a
jak je nutno přeloľit a poté spojit do nových verzí výsledné aplikace
- gcc
- GNU nebo i jiná verze překladače jazyka ``C''
- as
- překladač assembleru ( nejlépe téľ verze GNU )
- ld
- linker, program pro spojování částí strojového kódu do výsledného programu
- ar
- knihovní program pro správu fragmentů strojového kódu
- nm
- program pro výpis symbolických jmen pouľitých ve fragmentu strojového kódu
- bison nebo lex
- lexikální analyzátor pro překlad lexikálního popisu do jazyka
``C``, jeho přítomnost není absolutně nutná, protoľe GCC je jiľ dodáváno jak
se zdrojovými texty pro bison tak s přeloľenými soubory v jazyce ``C''.
- m4
- makro expander, jeho přítomnost není absolutně nutná
- makeinfo
- systém pro přípravu dokumentace do hypertextového formátu info - jeho
přítomnost je také volitelná
Veąkeré zde zmiňované programy jsou standardní součástí vąech distribucí systému
Linux. Například v distribuci Slackware se jedná o soubor disket s
názvem development. Větąina programů je dostupná i v binární formě pro větąinu
platforem včetně DOSu ( DJGPP ).
3.3 BINUTILS assembler, linker a daląí utility
Balík obsahuje prostředky pro tvorbu a správu fragmentů
strojového kódu pro cílovou platformu. Vstupními soubory jsou textové soubory
obsahující v textové formě popis programu v jednotlivých instrukcích cílového
procesoru. Vzájemné odkazy mezi funkcemi a daty jsou vyjádřeny pomocí symbolických
jmen. Tento tvar bude dále zkráceně nazýván jménem překladače assembler
( správněji jazyk symbolických adres ). Protoľe se větąina projektů skládá z
velkého mnoľství takovýchto souborů, není účelné, aby se při změně jednoho souboru
musela znova kompilovat celá aplikace. Řeąením je rozdělení překladu z assembleru
do absolutního strojového kódu cílového počítače na dvě části. Nejdříve jsou
soubory s assemblerem ( označované příponou .s nebo .S ) přeloľeny
( programem as ) do jednotlivých relokovatelných fragmentů strojového
kódu ( objektové soubory .o ). Tyto soubory jsou pak linkerem spojovány
do výsledné aplikace. Linker ( ld ) sloľí jednotlivé fragmenty, zjistí
jejich umístění ( adresy ) v cílové aplikaci a nahradí symbolické odkazy binárními
hodnotami. Protoľe velká část objektových souborů se opakuje ve vąech aplikacích,
jsou objektové soubory se standardními rutinami ukládány do knihoven ( program
ar ) a linker později sám rozhodne, které rutiny jsou volány aplikačním
programem a přísluąné fragmenty i s jejich daląími poľadavky přidá do výsledného
souboru.
3.3.1 Příprava instalace balíku BINUTILS
Balík se zdrojovými texty výąe zmiňovaných programů je moľné
získat na velkém mnoľství FTP servrů pod názvem binutils-2.7.0.3.tar.gz
pro popisovanou verzi. V naąí oblasti je nejlépe přístupný na mirroru `sunsite.mff.cuni.cz`.
Ve větąině případů je vľdy výhodnějąí pouľít nejnovějąí verzi. V současné době
je jiľ k dispozici verze 2.8.1.
Balík je komprimovaný ( programem GZIP ) UNIXový TAR archiv. Pro předpokládaný
hostitelský systém Linux a poľadované umístění zdrojových textů v adresáři
/usr/src/binutils-2.7.0.3 je nutné provést příkazy
- cd /usr/src
tar -xzf binutils-2.7.0.3.tar.gz
Vznikne adresář binutils-2.7.2.1 ve kterém jsou umístěny veąkeré zdrojové
texty kompilátoru programů. Pro uvaľovanou cílovou platformu MC68332 je nutné
nakonfigurovat kompilátor příkazy
- cd /usr/src/binutils-2.7.0.3
./configure --host=i486-linux --target=m68k-coff \
--build=i486-linux --exec-prefix=/usr --prefix=/usr \
--with-shared
Poslední příkaz zabírající tři řádky provede vlastní konfiguraci programů. Některé
údaje v něm nemusí být uvedeny, protoľe mohou být odvozeny implicitně, ale pro
daląí výklad je vhodná kompletní podoba. Nejdůleľitějąí je pro poľadovanou cílovou
platformu přepínač -target=m68k-coff.
V daląích odstavcích jsou vysvětleny jednotlivé aspekty konfigurace vedoucí
k výąe uvedenému příkazu. Vlastní kompilace je popsána v odstavci 3.3.7.
3.3.2 Kanonické jméno platformy
Pro popis platformy ( prostředí ) pouľívají téměř veąkeré GNU programy kanonického
popisu. Ten podává veąkerou informaci o typu procesoru, výrobci ( tvůrci ) operačního
systému a o vlastním operačním systému.
- CPU-COMPANY-SYSTEM
Ve velkém mnoľství případů je moľné některé části vypustit, protoľe jsou dostačně
určeny ostatními částmi. Například dále popisovaná verze překladače GCC rozpoznává
více jak 200 různých kombinací těchto tří parametrů. Jedná se o následující
procesory ( CPU )
- fx80
hppa1.0, hppa1.1
i370
i386, i486, i586
i860, i960
m68000, m68k
m88k
mips, mips64, mips64el,mips64orion, mips64orionel, mipsel
ns32k
pdp11
powerpc
powerpcle
pyramid
romp
rs6000
sparc, sparc64, sparclite
vax
we32k
xyes
Dále následují nejběľnějąí kombinace, které by se mohly čtenáři hodit. Hvězdičky
nahrazují části názvů, které mají alternativy. V hranatých závorkách jsou místa,
kde je moľný výběr z více znaků.
- i[345]86-*-bsd* i[345]86-*-freebsd* i[345]86-*-netbsd*
i[345]86-*-coff
i[345]86-*-linux
i[345]86-go32-msdos i[345]86-*-go32
m68k-*-aout*
m68k-*-coff*
Novějąí verze umoľňují i výběr přímo určený pro RT výkonné jádro RTEMS,
který je téměř shodný s volbou coff.
- m68k-*-rtems
Důleľitou informací, která je získána ze jména operačního systému je pouľitý
binární formát objektových a spustitelných souborů. Nejčastěji pouľívané formáty
budou popsány v následujících odstavcích.
3.3.3 Formáty objektových a spustitelných souborů
S vývojem prostředků pro kompilaci programů se vyvíjely
i formáty, ve kterých jsou ukládány relokovatelné a absolutní objektové soubory
a spustitelné programy. Postupně se zvyąovalo mnoľství informací, vhodných
pro optimalizaci, ladění, spojování objektových souborů a zavádění spustitelných
souborů. V současné době jsou nejroząířenějąí tři dále popsané formáty. Větąina
z nich je navrľena tak, ľe je lze přispůsobit pro uloľení strojového kódu určeného
téměř pro libovolný cílový procesor. Formáty se pro jednotlivé cílové procesory
mírně liąí, např. délkou ukládaných adres, pořadím bytů podle významnosti (
LSB, MSB ) atd. Například BINUTILS z obvyklé distribuce Linuxu
podporují následující formáty.
- elf32-i386 , a.out-i386-linux, coff-i386,
elf32-m68k, coff-m68k, ieee,
a.out-m68k-linux, a.out-sunos-big, elf32-sparc,
srec, symbolsrec, tekhex, binary, ihex, trad-core
Nejpouľívanějąí formáty jsou následující:
- aout
- původní UNIXový formát
formát je velmi závislý na cílové platformě ( systému i procesoru ). Rozděluje
se do velkého mnoľství podskupin. Knihovny za běhu mapované do prostoru aplikačního
programu musí být vľdy mapovány na pevnou adresu přidělenou centrální autoritou
( výrobcem systému ), programy musí jiľ při kompilaci znát napevno přidělené
adresy vstupních bodů knihoven. Pro ukládání relokovatelných fragmentů se větąinou
na těchto platformách pouľívá jiného proprietárního formátu.
- coff
- Common Object File Format
dobře přenositelný formát vhodný předevąím pro ukládání relokovatelných
a absolutních objektových formátů téměř pro vąechny druhy procesorů. Není nejvhodnějąí
pro ukládání spustitelných dynamicky linkovaných programů. Nevýhodou je, ľe
v ladící informaci o adresách přeloľených řádek zdrojového kódu neuvádí ve jménu
souboru i jméno adresáře. To se nepříznivě projeví při ladění velkých celků
se zdrojovými texty umístěnými v celém stromu adresářů.
- elf
- Executable and Linkable Formatzatím nejmodernějąí formát vhodný pro relokovatelné objektové soubory, spustitelné
programy, dynamicky linkované programy a knihovny. Umoľňuje mapovat knihovny
do libovolného neobsazeného místa běľícího programu. Program si můľe i zaľádat
o mapování roząiřující i knihovny podle jména i za běhu. Knihovna obsahuje kód
nezávislý na umístění ( PIC - Position Independent Code ). Vstupní body knihoven
jsou linkovány i za běhu přes symbolická jména.
Je moľné tak zvané Late Bindings. To znamená, ľe i vlastní hledání knihovny
a vyčlenění prostoru je provedeno aľ při pokusu o volání některého vstupního
bodu.
- srec, ihex, tekhex, binary
-
formáty obsahující pouze obraz kódu a inicializovaných dat v paměti cílového
procesoru. Jsou vhodné pro přenos dat například do programátoru paměti EPROM,
nebo přímo do paměti cílového procesoru, který neobsahuje inteligentnějąí zavaděč
programů.
Protoľe formátů je velké mnoľství a operace s nimi v assembleru, linkeru a ostatních
programech je moľné zobecnit obsahuje balík BINUTILS knihovnu s obecným interfacem
pro přístup k libovolnému formátu. Tato knihovna se jmenuje BFD ( Binary
Format Driver ) a můľe být k jednotlivým programům balíku linkována dynamicky.
V případě Linuxu je uloľena například v souboru /usr/lib/libbfd.so.2.7.0.3.
Při konfiguraci balíku BINUTILS je nutné rozhodnout, které formáty
bude tato knihovna zpracovávat. Ve větąině případech je vhodný formát nalezen
přímo z kanonického jména platformy. Je vąak moľné poľadované formáty explicitně
specifikovat při konfiguraci programem configure jak bude popsáno v části
3.3.6.
3.3.4 Platformy build, host a target
Pro konfiguraci a kompilaci je nutné rozhodnout na které
platformě bude balík BINUTILS a ostatní části GNU vývojového
prostředí kompilovány ( build ), později provozovány ( host ) - spouątěny programy
as, ld, gcc atd. a pro kterou cílovou platformu mají být
určeny výsledné objektové soubory a vytvořené spustitelné programy ( target
). Větąinou je kompilována pouze nová verze kompilátoru a utilit na určité platformě,
pak jsou vąechna tato určení shodná a mohou být zjiątěna automaticky. Ve zde
popisovaném případě je poľadavek vytvořit kříľový překladač ( cross compiler
), který je kompilován na systému Linux, bude provozován na systému
Linux a výsledné aplikace mají být určeny pro systém s procesorem MC68332.
Tím je vysvětlena i kombinace build, host a target v sekci 3.3.1.
Daląí moľností, kdy jsou vąechny tři platformy rozdílné je takzvaný canadian
cross. Teoreticky je například moľné kompilovat GNU prostředí kompilovat
na systému Linux, při čemľ vzniklé programy budou pouľívány pod systémem
DOS pro tvorbu řídících aplikací provozovaných na systému s MC68332.
Hlavičkové soubory pro jednotlivé platformy se jsou pojmenovány mh- < platforma > .h
( pro hostitelskou platformu ) a mt- < platforma > .h
( pro cílovou platformu ) a nacházejí se v adresáři /usr/src/binutils-2.7.0.3/config.
3.3.5 Standardní umístění souborů
Protoľe jsou nástroje určeny předevąím pro UNIXové systémy,
počítají se standardním umístěním souborů ve stromové struktuře adresářů. UNIX
předpokládá pouze jeden kořen vąech adresářů. Daląí disky a sí»ové svazky
se připojují pouze připojením ( mount ) k některému z jiľ existujících adresářů.
Zároveň je počítáno i s provázáním stromu více počítačů i s různou architekturou.
Proto jsou jednotlivé programové balíky rozděleny na části závislé na hostitelské
platformě, závislé na cílové platformě, sdílené v síti, privátní k danému počítači
atd. Protoľe je standardní systém adresářů definován normou, znají programy
přímo absolutní cesty k volaným programům.
Z výąe uvedeného vyplývá, ľe je nutné vąechny části vývojového prostředí nakonfigurovat
pro shodnou strukturu adresářů. Zároveň pro budoucí kombinaci jednotlivých částí
s originálními programy z distribuce Linuxu je výhodné dodrľet konfiguraci
pouľitou pro tyto programy.
Části balíku BINUTILS závislé na cílové platformě jsou umístěny do substromu
pod adresářem < prefix > / < target > .
V případě Linuxu je pouľíván prefix pro základní vývojové prostředky /usr.
Celá cesta pak vypadá /usr/m68k-coff. V podadresáři bin budou
umístěny jednotlivé spustitelné programy ( as, gasp, ld,
nm, ranlib, size a strip ). V podadresáři lib
budou později umístěny knihovny funkcí pro cílovou platformu. Zároveň zde musí
být adresář nebo odkaz na adresář se jménem ldscripts. V tomto adresáři
hledá linker při spojování fragmentů kódu formát a popis uloľení jednotlivých
oblastí do výsledného souboru.
Ostatní programy nezávislé na cílové platformě mohou být umístěny do adresáře
< exec-prefix > / < bin > .
Není-li exec-prefix specifikován je pouľit prefix. Při instalaci
těchto programů je nutné dát pozor, aby nebyla naruąena funkčnost vývojových
prostředků pro ostatní platformy. Pro instalaci v prostředí nevyuľívajícím
standardní systém adresářů je moľné instalovat i programy i pro více platforem
do jednoho adresáře. Pak je moľné programy odliąit pomocí předpony a přípony
přímo ve jménu programu ( program-prefix a program-sufix ).
3.3.6 Parametry programu configure pro BINUTILS
Popis veąkerých moľných parametrů programu by vydal na samostatnou
knihu, proto zde budou uvedeny jen nejdůleľitějąí parametry, které má význam
měnit.
Program je ve skutečnosti soubor skriptů pro interpretr Berkley Shell systému
UNIX. Spouątí se příkazem ./configure2, který je následován poľadovanými parametry. Pro neuvedené parametry
jsou vľdy nalezeny optimální implicitní hodnoty. V následujícím textu jsou uvedeny
v hranatých závorkách.
- -help
- vypíąe nápovědu [neaktivní]
- -build=BUILD
- platforma, pro kompilaci prostředků [BUILD=HOST]
- -host=HOST
- provozní platforma, na které budou prostředky provozovány [zjiątěna přes config.guess]
- -target=TARGET
- cílová platforma prostředků, vývojového prostředí [TARGET=HOST]
- -prefix=MYDIR
- základní adresář, kam bude provedena instalace prostředků [/usr/local]
mají-li být prostředky kombinovány s ostatními vývojovými prostředky i
pro jiné architektury, je nutné aby vąechny měly MYDIR shodné. Standardní umístění
pod systémem Linux je pod adresářem /usr.
- -exec-prefix=MYDIR
- programy nezávislé na cílové platformě MYDIR [/usr/local]
pouľito např. v případě nutnosti rozliąení programů pro jednotlivé hostitelské
platformy.
- -norecursion
- provést konfiguraci pouze aktuálního adresáře [recurse]
- -program-prefix=FOO
- přidat FOO před jména instalovaných programů [""]
pro cross kompilátory je v novějąích verzích přidán implicitně prefix
podle jména cílové platformy, pro uvaľovanou konfiguraci m68k-coff-.
- -program-suffix=FOO
- přidat FOO za jména instalovaných programů [""]
- -srcdir=DIR
- cesta k zdrojovým textům balíku [. nebo ..]
výhodné například při kompilaci z read-only zdroje, např. CD-ROM
- -tmpdir=TMPDIR
- pouľívat adresář TMPDIR pro dočasné soubory [/tmp]
- -infodir=DIR
- hypertextovou dokumentaci info do adresáře DIR [PREFIX/info]
- -mandir=DIR
- klasickou dokumentaci man dokumentaci do DIR [PREFIX/man]
- -nfp
- konfigurace pro softwarovou desetinnou aritmetiku [hard float]
- -with-FOO, -with-FOO=BAR
- kompilovat s balíkem FOO ( parametrem BAR )
- -without-FOO
- balík FOO není k dispozici pro hostitelskou platformu
- -enable-FOO, -enable-FOO=BAR
- kompilovat s vlastností FOO ( parametrem BAR
)
- -disable-FOO
- nakázat vlastnost FOO
- -enable-targets
- povolit podporu pro jednotlivé cílové platformy
jedná se o podporu formátů a procesorů v knihovně libbfd, například konfigurace
pro MC688332 a i386 Linux je
-enable-targets=m68k-coff,i386-linux
- -enable-shared
- kompilovat se sdílenou knihovnou BFD
- -enable-commonbfdlib
- vytvořit sdílené knihovny BFD/opcodes/libiberty
- -with-mmap
- pouľívat mmap pro vstupní soubory v BFD
3.3.7 BINUTILS - vlastní kompilace a instalace
Tato část je relativně jednoduchá. Kompilace je spuątěna
příkazem
- cd /usr/src/binutils-2.7.0.3
make
Instalaci je moľno provést příkazem make install. Pro kontrolu kolizí
je vąak výhodnějąí pouze zjistit co je třeba kam zkopírovat a zkontrolovat případné
kolize s původními programy. Zjiątění příkazů, které by byly vykonány se provede
přidáním přepínače -n. Pak příkaz i se zachycením výstupu vypadá následovně
- make install -n | less
Je-li pouľito sdílené knihovny BFD s vhodnou kombinací pouľívaných platforem,
jsou teoreticky pro přidání daląí platformy specifické pouze soubory as
a ld. Vąe ostatní můľe být nahrazeno symbolickými linkami.
3.3.8 GNU Assembler ``as''
Tento program je obvykle volán pouze přes integrovaný překladač gcc.
Přesto je vhodné pro některé účely znát jeho pouľití. Pro přísluąnou cílovou
platformu je nutné volat správný program ( např. /usr/m68k-coff/bin/as
). Stručnou nápovědu je moľné získat voláním programu s parametrem -help.
Pro kompletní popis je nutné pouľít dokumentaci ve formátu info ( prohlíľet
např. programem info nebo v editorech emacs a jed klávesami
< ctrl+h > < i > ). Stručně
: na řádku se bez přepínače zadávají vstupní soubory, za přepínač -o
se zadává jméno výstupního souboru. Pro zde uvaľovanou platformu jsou důleľité
přepínače mezi variantami procesoru, které povolují překlad nových instrukcí
oproti MC68000. Jedná se o přepínače typu -m68332, -m68020, -m68881
( pro přísluąnou FPU ) atd. Tvorbu kódu nezávislého na umístění ( např. sdílené
knihovny ELF viz 3.3.3 ) se vyľádá přepínačem -pic. Pro
překlad souborů s originální ( Motorola ) syntaxí instrukcí ( nikoli AT&T a
UNIX ) je moľno pouľít přepínač -M.
3.3.9 GNU Linker ``ld''
Opět se jedná o program závislý na platformě ( např. /usr/m68k-coff/bin/ld
). Nápověda opět -help nebo ve formátu info. Bez přepínače se zadávají
jednotlivé vstupní souboru ( *.o a lib* ). Implicitní
jméno vytvořeného spustitelného souboru a.out lze změnit přepínačem -o.
Knihovny lze uvádět také za přepínačem -l ( pak se uvádí bez přípon a
počátečního lib ), které jsou hledány v adresářích definovaných za přepínači
-L. Konfigurace cílového pamě»ového prostoru ( počátek, délka, sekce,
RAM, ROM atd. ) je definována ve skriptu v adresáři ldscripts ( např.
m68kcoff.x ). Jiný neľ implicitní skript lze vybrat přepínačem -T a je
hledán v knihovních adresářích. Adresář ldscripts obsahuje pro kaľdou
platformu více skriptů, které se liąí příponami:
- *.x
- normální spustitelný soubor ( program )
- *.xr
- pro relokovatelný výstup z linkeru s přepínačem -r, výstupní
formát musí podporovat relokovatelný kód.
- *.xu
- relokovatelný kód bez vytvoření konstruktorů, přepínač -Ur
- *.xn
- sekce .data a .text mohou být kombinovány, přepínač -n
- *.xbn
- totéľ, ale s přepínačem -N
- *.xs
- pro kompilaci sdílené knihovny pokud je přepínač -shared
Výstupní formát lze změnit přepínačem -oformat . Je-li kompilována sdílená
knihovna musí být nastaveno -shared a můľe být definováno -soname
( interní jméno knihovny ), při kompilaci programů je moľné linkovat proti statickým
knihovnám -Bstatic ( knihovny lib*.a ) nebo dynamickým -Bdynamic
( lib*.so ).
Pro embeded aplikace je nutné vytvořit správný ldscript a nebo lze určit počátek
paměti EPROM, RAM a oblasti zásobníku následujícími přepínači -Ttext 0x10000
-Tdata 0x18000 -Tbss 0x1C000.
3.3.10 Konvertor ``objcopy''
Objcopy je velmi jednoduchý program, který otevře vstup a výstup přes BFD ve
specifikovaném formátu a překopíruje veąkerou informaci, kterou je moľné do
výstupního formátu uloľit. Například vytvoření S-record souboru pro download
programu do testovací desky s lokálním monitorem schopným tento formát přijmout
- objcopy --input-target=m68k-coff \
--output-target=srec -S a.out a.srec
Daląí uľitečné přepínače -g a -S pro potlačení ladících informací.
-R pro nekopírování určité sekce.
Daląí příklad je vytvoření obrazu paměti v Intel HEX formátu pro naprogramování
do paměti EPROM
- objcopy --input-target=m68k-coff \
--output-target=ihex a.out a.hex
Přepínače -byte a -interleave umoľňují řeąit rozloľení dat do
více paralelně řazených pamětí. Přepínače -set-start a -adjust-start
umoľňují vybrat jen určitou část z dat se správným posunutím.
Program podporuje libovolnou konverzi formátů, můľeme vąak narazit na ztrátu
některých informací, jiné konvence jmen ( např. počáteční znak ``_'' před
jménem lze programem objcopy potlačit ). Pro relokovatelné soubory můľe dojít
k ztrátě relokačních informací.
3.3.11 BINUTILS - daląí programy
- objdump
- výpis obsahu souboru s fragmentem kódu nebo spustitelného programu
např. -source vypíąe vąechny sekce s kódem ve formátu listingu assembleru
proloľené řádkami zdrojového kódu ( jsou-li zdrojové soubory k dispozici )
- nm
- výpis symbolických jmen pouľitých v daném binárním souboru
- size
- výpis velikost jednotlivých sekcí programu
- ar
- program pro správu knihoven
- ranlib
- vytvoří index symbolických jmen v knihovně pro zvýąení rychlosti při
sestavování programů
- strip
- vymazání ladících informací
- gasp
- GNU assembler macro preprocessor
3.4 GCC překladač jazyka ``C''
V současné době je základním jazykem pro psaní systémových programů jazyk ``C'',
jehoľ dostupnost na téměř vąech platformách umoľňuje i přenositelnost
aplikací. Překladač GCC je navrľen tak, aby umoľňoval i snadnou svojí
vlastní přenositelnost i na systémy, na kterých zatím nebyl provozován a i pro
nové systémy, pro které zatím jiný překladač neexistuje. Tato vlastnost je velmi
výhodná i pro vývoj řídících aplikací, kde se implementace samotného kompilátoru
GCC na cílové platformě nepředpokládá.
Kvalita výsledného kódu v assembleru je přinejmenąím srovnatelná s větąinou
komerčních překladačů. Překladač je postupně optimalizován a roząiřován
o daląí cílové ( target ) a hostitelské ( host ) platformy.
V daląím textu bude uvaľována verze 2.7.2.1, operační systém hostitelského
počítače Linux a cílová platforma MC68332. V současné době
jiľ existuje verze 2.8.0 a nová vývojová větev EGCS. Verze
EGCS zahrnuje mnoľství vylepąení a daląích optimalizací. Předpokládá
se, ľe po důkladném otestování budou postupně vylepąení přejímána do stabilní
vývojové větve GCC.
3.4.1 GCC - příprava instalace crosscompileru
Kříľový překladač je taková konfigurace, kdy cílová platforma je jiná neľ hostitelská
platforma vlastního překladače. Balík se zdrojovými texty kompilátoru je moľné
získat na velkém mnoľství FTP servrů pod názvem gcc-2.7.2.1.tar.gz
pro popisovanou verzi. V naąí oblasti je opět nejlépe přístupný na mirroru `sunsite.mff.cuni.cz`.
Balík je komprimovaný ( programem GZIP ) UNIXový TAR archiv. Pro předpokládaný
hostitelský systém Linux a poľadované umístění zdrojových textů v adresáři /usr/src/gcc-2.7.2.1
je nutné provést příkazy
- cd /usr/src
tar -xzf gcc-2.7.2.1.tar.gz
Vznikne adresář gcc-2.7.2.1 ve kterém jsou umístěny veąkeré zdrojové texty kompilátoru
GCC. Pro uvaľovanou cílovou platformu MC68332 je nutné nakonfigurovat kompilátor
příkazy
- cd /usr/src/gcc-2.7.2.1
./configure --host=i486-linux --target=m68k-coff \
--build=i486-linux --with-gnu-ld --with-gnu-as --nfp
Druhý z příkazů je dlouhý přes dvě řádky. Některé údaje v něm nemusí být uvedeny,
protoľe mohou být odvozeny implicitně. Nejdůleľitějąí je pro poľadovanou cílovou
platformu opět přepínač -target=m68k-coff.
3.4.2 Parametry programu configure pro GCC
Program je opět soubor skriptů pro interpretr Berkley Shell
systému UNIX. Spouątí se příkazem ./configure, který je následován poľadovanými
parametry. Způsob zadávání jmen platforem je shodný s balíkem BINUTILS
viz 3.3.4. Pro neuvedené parametry jsou vľdy nalezeny optimální
implicitní hodnoty. V následujícím textu jsou uvedeny v hranatých závorkách.
- -help
- vypíąe nápovědu [neaktivní]
- -build=BUILD
- platforma, pro kompilaci prostředků [BUILD=HOST]
- -host=HOST
- provozní platforma, na které budou prostředky provozovány [zjiątěna přes config.guess]
- -target=TARGET
- cílová platforma prostředků, vývojového prostředí [TARGET=HOST]
- -prefix=MYDIR
- základní adresář, kam bude provedena instalace prostředků [/usr/local]
mají-li být prostředky kombinovány s ostatními vývojovými prostředky i
pro jiné architektury, je nutné aby vąechny měly MYDIR shodné. Standardní umístění
pod systémem Linux je pod adresářem /usr.
- -local-prefix=MYDIR
- kde se nalézá adresář include s lokálními hlavičkovými
soubory [/usr/local]
je nutné, aby podadresář include neobsahoval systémové hlavičkové soubory, proto
MYDIR nesmí být /usr
- -exec-prefix=MYDIR
- programy nezávislé na cílové platformě MYDIR [/usr/local]
pouľito např. v případě nutnosti rozliąení programů pro jednotlivé hostitelské
platformy.
- -norecursion
- provést konfiguraci pouze aktuálního adresáře [recurse]
- -program-prefix=FOO
- přidat FOO před jména instalovaných programů [""]
opět pro nové verze GCC platí, ľe pro crosscompiler je automaticky předřazeno
jméno cílové platformy
- -program-suffix=FOO
- přidat FOO za jména instalovaných programů [""]
- -srcdir=DIR
- cesta k zdrojovým textům balíku [. nebo ..]
výhodné například při kompilaci z read-only zdroje, např. CD-ROM
- -tmpdir=TMPDIR
- pouľívat adresář TMPDIR pro dočasné soubory [/tmp]
- -infodir=DIR
- hypertextovou dokumentaci info do adresáře DIR [PREFIX/info]
- -mandir=DIR
- klasickou dokumentaci man dokumentaci do DIR [PREFIX/man]
- -nfp
- konfigurace pro softwarovou desetinnou aritmetiku [hard float]
- -with-FOO, -with-FOO=BAR
- kompilovat s balíkem FOO ( parametrem BAR )
- -without-FOO
- balík FOO není k dispozici pro hostitelskou platformu
- -enable-FOO, -enable-FOO=BAR
- kompilovat s vlastností FOO ( parametrem BAR
)
- -disable-FOO
- zakázat vlastnost FOO
- -with-gnu-as
- GCC bude vyuľívat GNU assembler
má smysl pouze pro systémy, pro které není GNU toolchain základním vývojovým
prostředím. GNU assembler musí být jiľ nainstalován z balíku BINUTILS.
- -with-gnu-ld
- totéľ pro GNU linker
3.4.3 Soubory pouľívané pro konfiguraci GCC
Při kompilaci je zavedena cesta k hlavičkovým souborům do adresáře config,
ve kterém je uloľena větąina informací o specifických platformách. V základním
adresáři se zdrojovými texty GCC jsou konfiguračním skriptem vytvořeny odkazy
na tyto soubory.
Při konfiguraci je vytvořen v základním adresáři zdrojového textu GCC soubor
config.h, který přes direktivu #define zpřístupňuje soubor definicí
pro hostitelskou platformu < CPU > /xm- < SYSTEM > .h
z adresáře config. Pro zde uvaľovanou konfiguraci to bude soubor i386/xm-linux.h.
Tento soubor dále zpřístupňuje informace ze souborů obsahujících informace o
procesoru < CPU > /xm- < CPU > .h
a obecné informace o hostitelském systému xm- < SYSTEM > .h,
v předkládaném případě i386/xm-i386.h a xm-linux.h. Soubor s definicemi
pro hostitelský procesor obsahuje daląí odkaz na informace o cílové platformě
kompilátoru tm.h.
Cílová platforma je popsána podobným postupem jako platforma hostitelská. Soubor
tm.h v základním adresáři se odkazuje na soubor < CPU > / < SYSTEM > .h.
V popisované konfiguraci m68k/m68k-coff.h, coľ je způsobeno tím, ľe není
vytvářen kompilátor pro konkrétní cílový systém, ale pro kombinaci procesoru
a jednoho z moľných formátů objektových souborů. Tento soubor se větąinou odkazuje
na několik daląích souborů obsahujících konkrétní informace o cílovém procesoru
< CPU > / < CPU > .h, obecné
informace o cílovém systému < SYSTEM > .h a o
pouľitém formátu objektových souborů.
Soubor tconfig.h obsahuje konfiguraci pouľitou jiľ zkompilovaným kompilátorem
při kompilaci knihoven. V uvaľovaném případě je jeho obsah shodný s tm.h.
Při konfiguraci je také ze souboru Makefile.in vytvořen soubor Makefile, do
kterého mohou být přidány části závislé na hostitelské a cílové platformě uloľené
v adresářích pro přísluąné procesory a nesoucí jména x- < HOST >
a t- < TARGET > .
V adresáři pro cílový procesor se nachází také vlastní popis vlastností a instrukcí
cílového procesoru v souboru < CPU > .md. Tento
popis je doplněn algoritmy pro některé důleľité operace (např. generování vstupního
a výstupního bloku podprogramu) v souboru < CPU > .c.
3.4.4 GCC - vlastní kompilace
V nejjednoduąąím případě stačí spustit kompilaci ze základního adresáře balíku
GCC příkazem make. Pokud jsou poľadovány jen některé z variant kompilátoru
je je moľné specifikovat v příkazu
- make LANGUAGES="<LIST>"
Poloľka < LIST > můľe obsahovat libovolnou kombinaci
následujících variant oddělených mezerami
- c
- kompilátor standardního jazyka ``C''
- c++
- kompilátor jazyka C++
- objective-c
- kompilátor verze objective-C
- proto
- povoluje kompilace programů protoize a unprotoize
tyto programy slouľí pro převod zdrojových textů z tvaru Kerningham&Ritchie
do tvaru ANSI a naopak
Je-li kompilátor kompilován na cílové platformě je vhodné pouľít daląích kompilací,
k vyloučení vlivu předcházejících verzí ( nebo jiného neľ GNU kompilátoru )
na výsledný kompilátor. To se provádí opakováním kompilace kompilátoru kompilátorem
vzniklým v předchozí etapě. Zároveň je moľné postupně přidat stupeň optimalizace
kódu výsledného kompilátoru. Daląí kompilace se provede příkazem
- make stage1
make CC="stage1/xgcc -Bstage1/" CFLAGS="-g -O2"
výsledky minulé etapy jsou uloľeny do adresáře stage1 a jsou pouľity
pro daląí kompilaci. Pro platformy bez hardwarové podpory výpočtů v plovoucí
řádové čárce můľe být nutné specifikovat při přechodu z jiného neľ GNU kompilátoru
emulaci těchto výpočtů modifikací druhého příkazu
- make CC="stage1/xgcc -Bstage1/" CFLAGS="-g -O2 \
-msoft-float"
Pro získání jistoty o kvalitě výsledného kompilátoru je doporučeno provést třetí
kompilaci
- make stage2
make CC="stage2/xgcc -Bstage2/" CFLAGS="-g -O2"
a zkontrolovat, jestli se výsledné objektové soubory shodují s těmi, které vznikly
v předchozí etapě a jsou uloľeny v adresáři stage2. Tato komparace nemusí
být triviální na platformách, které ukládají do objektových souborů datum kompilace.
Pak je nutné provést komparaci následujícím pomalejąím způsobem
- make compare
Libovolná zjiątěná diference je chybou a měla by být oznámena vývojářům překladače
GCC.
V novějąících verzích lze provést několikaúrovňový překlad s kontrolou činnosti
výsledného kompilátoru jediným poľadovaným cílem programu make bootstrap.
3.4.5 GCC - kompilace crosscompileru
GCC je schopno kompilovat zdrojový kód pro jinou cílovou platformu neľ je platforma,
na které je provozováno. Tomuto způsobu práce se říká crosscompilace a je potřebný
pro cílové platformy, pro které jeątě neexistuje kompilátor jazyka ``C'',
nebo na kterých nemůľe být kompilátor provozován. Příkladem jsou řídící a regulační
jednotky.
S kompilací crosscompileru mohou nastat problémy, má-li cílová platforma jinou
délku operačního slova nebo kdyľ popis cílové platformy správně nevyuľívá moľnosti
emulace plovoucí řádové čárky při kompilaci.
Konfigurace se provede pro uvaľovanou cílovou platformu m68k-coff například
příkazem ( viz 3.4.2 )
- ./configure --target=m68k-coff
V době kompilace by jiľ měly být nainstalovány programy z balíku BINUTILS (
viz 3.3 ) v adresáři < prefix > / < target > /bin.
Pro uvaľovaný případ /usr/m68k-coff.
Jsou-li k dispozici knihovny a hlavičkové soubory pro cílovou platformu, mohou
být umístěny do adresářů < prefix > / < target > /lib
respektive < prefix > / < target > /include.
Důleľité jsou také soubory pro spuątění programu *crt*.o.
Problémy také mohou nastat s knihovnou emulací některých operací ( např. operace
v plovoucí řádové čárce nebo operace celočíselného násobení a dělení ) libgcc.a
pro některé cílové platformy. Ve větąině případů vąak můľe být tato knihovna
prázdná nebo vybudována ze zdrojových textů dodávaných spolu s GCC.
Spuątění vlastní kompilace se provede stejně jako při kompilaci obyčejného kompileru
- make LANGUAGES="<LIST>"
Nejsou-li k dispozici hlavičkové soubory pro tvorbu libgcc.a, kompilace
se v určité fázi přeruąí. Některé starąí verze GCC také předpokládají jiľ existenci
alespoň prázdné knihovny libgcc.a. Pro daląí pokračování je nutné vytvořit
v adresáři < prefix > / < target > /lib
alespoň prázdnou knihovnu příkazem
- ar -cd libgcc.a dummy
Po opětovném spuątění příkazem make kompilace pokračuje a v daląích fázích
doplní knihovnu libgcc.a. Úplnost knihovny zkontroluje kompilací testovacího
programu libgcc1-test. Dojde-li při jeho linkování k chybě, znamená to,
ľe ne vąechny potřebné rutiny byly do knihovny doplněny a náprava je moľná pouze
jejím manuálním doplněním.
Z hlavičkových souborů je k dokončení kompilace nutný soubor float.h.
Tento soubor můľe být získán po zkompilování a spuątění testovacího programu
enquire na cílové platformě. Tento postup není větąinou pro řídící systémy
moľný, pak je nutné pouľít jiľ předdefinovaný hlavičkový soubor float.h.
Tento soubor pouľitelný pro větąinu cílových platforem je k dispozici z cross-gcc
distribuce firmy CYGNUS.
Při kompilaci crosscompileru není moľné provést následující etapy kompilace,
protoľe jiľ zkompilovaný kompiler neumí kompilovat pro hostitelskou platformu.
Po správné instalaci crosscompileru a nové konfiguraci GCC je vąak moľné zkompilovat
kompiler určený pro běh na cílové platformě.
3.4.6 GCC - instalace crosscompileru
Nejjednoduąąí je spustit instalaci příkazem
- make install
Je vąak vhodné vědět, do kterých adresářů jsou uloľeny jednotlivé programy a
soubory kompileru. Základní adresář, do kterého je GCC instalováno, je adresář
< prefix > /lib/gcc-lib/ < target > / < version > .
V uvaľované konfiguraci /usr/lib/gcc-lib/m68k-coff/2.7.2.1. V tomto adresáři
se budou nacházet následující soubory. Programy gcc a g++
s případnou předponou jsou uloľeny do adresáře < exec-prefix >
pro binární programy.
- cpp
- makro preprocesor jazyka ``C''
- cc1
- vlastní kompilátor jazyka ``C''
- cc1plus
- kompilátor jazyka C++
- cc1obj
- kompilátor jazyka objective-C
- gcc-cross
- obálka pro volání vąech verzí crosscompileru
v případě normálního ( nativního ) kompiléru se program jmenuje gcc,
v novějąích verzích je pro crosscompiler pouľito jméno < target > -gcc,
například m68k-coff-gcc, volba záleľí na volbě parametru program-prefix
při konfiguraci
- g++-cross
- obálka pro přímou kompilaci zdrojových textů v jazyce C++
- specs
- popis akcí spouątěných programem gcc-cross
tento soubor obsahuje vztahy mezi přepínači pro program gcc-cross a
ostatní jím volané programy ( cc1, cc1plus, as, ld
). V souboru jsou obsaľeny i informace o knihovnách, které je nutné přidat pro
softwarovou emulaci operací s plovoucí řádovou čárkou, knihoven a startovacích
souborů pro umoľnění ladění.
- libgcc.a
- knihovna s emulačními a pomocnými funkcemi
tyto funkce jsou volány z přeloľeného programu v případech, kdy přímé vloľení
sekvence instrukcí není moľné nebo celková délka je přílią velká ( např. emulace
operací v plovoucí řádové čárce ). Tato knihovna můľe být uloľena v několika
variantách pro různé kombinace přepínačů -m zpřesňujících variantu cílové
architektury. Varianty jsou pak uloľeny v podadresářích pojmenovaných jmény
těchto přepínačů.
- libobjc.a
- knihovna pomocných funkcí pro kompilátor objective-C
- m < variant >
- adresáře obsahující varianty knihovny
libgcc.a
- include
- hlavičkové soubory pro některé funkce závislé i na kompilátoru
například operace pro práci s proměnným počtem vstupních argumentů funkcí
4 BDM vývojové rozhraní a GDB
konec textu
References
- [1]
- M68300 Family MC68332, MOTOROLA, INC. 1995
http://www.mot-sps.com/
- [2]
- CPU32 REFERENCE MANUAL MOTOROLA, INC., 1990, 1996
- [3]
- TPU TIME PROCESSOR UNIT REFERENCE MANUAL, MOTOROLA, INC., 1996
- [4]
- MCF5206 USER'S MANUAL MOTOROLA, INC., pre-final version
- [5]
- RCPU RISC CENTRAL PROCESSING UNIT REFERENCE MANUAL, MOTOROLA, INC. 1994, 1996
- [6]
- Great Microprocessors of the Past and Present (V 10.1.1),
John Bayko (Tau), March 1998,
http://www.cs.uregina.ca/~bayko/
- [7]
- Frequently Asked Questions FAQ, For the Internet USENET newsgroup: comp.sys.m68k,
Robert Boys, Ontario, CANADA, August 24, 1995, Version 19,
http://www.ee.ualberta.ca/archive/m68kfaq.html
- [8]
- Debugging with GDB The GNU Source-Level Debugger Fifth Edition,
for GDB version 4.17 , Richard M. Stallman and Roland H. Pesch, April 1998
Copyright (C) 1988-1998 Free Software Foundation, Inc
Free Software Foundation 59 Temple Place - Suite 330, Boston, MA 02111-1307
USA
ISBN 1-882114-11-6
Contents
1 Popis mikrokontroléru
1.1 Přehled vlastností jednotlivých modulů
1.2 Stručný popis CPU32
1.2.1 Registry a reľimy procesoru
1.2.2 Adresace - konvence
1.2.3 Reľimy adresace
1.2.4 Instrukční soubor
1.2.5 Výkonnějąí následníci CPU32
1.3 Integrační modul (SIM)
1.4 Časovací koprocesor (TPU)
1.5 Komunikační modul (QSPI)
2 Přehled vývojových prostředků
2.1 Hardwarové prostředky
2.2 Prostředky pro vývoj software
2.3 Ladění aplikací
3 GNU Tool Chain
3.1 Projekt GNU a FSF Inc
3.2 Programy nutné pro přípravu vývojového prostředí
3.3 BINUTILS assembler, linker a daląí utility
3.3.1 Příprava instalace balíku BINUTILS
3.3.2 Kanonické jméno platformy
3.3.3 Formáty objektových a spustitelných souborů
3.3.4 Platformy build, host a target
3.3.5 Standardní umístění soborů
3.3.6 Parametry programu configure pro BINUTILS
3.3.7 BINUTILS - vlastní kompilace a instalace
3.3.8 GNU Assembler ``as''
3.3.9 GNU Linker ``ld''
3.3.10 Konvertor ``objcopy''
3.3.11 BINUTILS - daląí programy
3.4 GCC překladač jazyka ``C''
3.4.1 GCC - příprava instalace crosscompileru
3.4.2 Parametry programu configure pro GCC
3.4.3 Soubory pouľívané pro konfiguraci GCC
3.4.4 GCC - vlastní kompilace
3.4.5 GCC - kompilace crosscompileru
3.4.6 GCC - instalace crosscompileru
4 BDM vývojové rozhraní a GDB
List of Figures
1 Funkční bloky 68332
2 Uľivatelský model CPU32
3 Systémový model CPU32
4 Stavový registr
5 Časovací koprocesor TPU
6 Externí emulátor
7 Interní BDM emulátor
Footnotes:
1
Referenčním zdrojem informací je manuál firmy Motorola viz [1].
2
znaky tečka a lomeno ``./'' před jméne programu jsou nutné, protoľe větąina
instalací UNIXu má nastaveno v cestě pro hledání spustitelných souborů
nejdříve standardní adresáře a aľ na konci je uveden aktuální adresář. Přidáním
části cesty k programu se zaručí, ľe nebude spuątěn jiný program, neľ právě
ten v aktuálním adresáři.
File translated from TEX by TTH, version 1.52.