Pro jednotlivé třídy (písmenka) budeme uvažovat gaussovský model distribuce: p(x|k) ~ N(μk, σk). Odhad tvaru distribuce závisí na dvou parametrech, μk a σk, které odhadneme metodou maximální věrohodnosti.
Odhadnuté apriorní pravděpodobnosti a hustoty pravděpodobnosti použijeme ke klasifikaci testovacích dat pomocí bayesovské strategie.
Zadání
- Napište formulaci maximálně věrohodného odhadu parametrů
μk a
σk
distribucí p(x|A),
p(x|C):
Nápověda: (μk,σk) = argmax P({x1,x2 ...
(musíte být schopni formulaci vysvětlit cvičícím)
- Stáhněte si a nahrajte do Matlabu soubor
data_33rpz_cv04.mat.
- Pro všechny trénovací množiny proveďte:
- Spočtěte apriorní pravděpodobnosti P(A) a P(C).
- Metodou maximální věrohodnosti odhadněte parametry μk a σk distribucí p(x|A) a p(x|C).
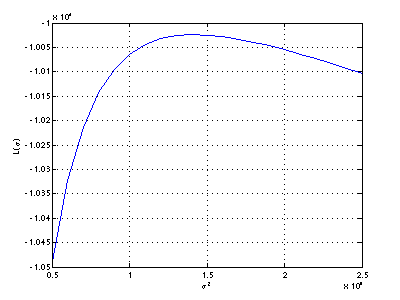
- Pro výše vypočtené μk
vykreslete odhadnutou střední věrohodnostní funkci
L (viz [1]) jako funkci
σk. Stačí jen pro
jednu třídu, např. pro třídu A.
- Do jednoho grafu vykreslete odhadnuté distribuce
p(x|A),
p(x|C) společně s
normalizovaným histogramem trénovacích dat.
- Na základě získaných odhadů klasifikujte testovací data
pomocí bayesovské strategie a vypište chyby.
Bonusová úloha
- Zopakujte body 2.1, 2.2 a
4 pro dvourozměrné
měření X = (x,
y)T
y = (součet hodnot pixelů v horní polovině obrázku) - (součet hodnot pixelů v dolní polovině obrázku)
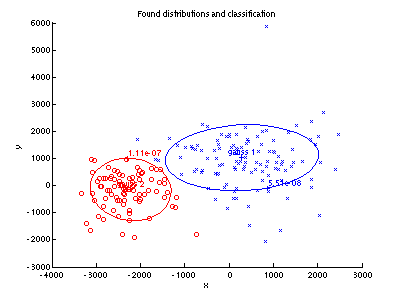
- Podobně jako v bodě 3 zobrazte
odhadnuté distribuce
(použijte funkci pgauss)
a testovací vzorky (použijte funkci
ppatterns).
Doporučená literatura
[1] Maximálně věrohodný odhad[2] Archív zápisů z přednášek rozpoznávání (33RPZ)
Created by Jan Šochman. Last modification 15.10.2008.