Poznámky k používání funkce gsmo:
- Funkce je součástí STPR toolboxu, ale k tomu, aby fungovala, je potřeba zkompilovat soubor gsmo_mex.c do MEXu, což nemusí na vašich počítačích jít. Zkompilovaný soubor si můžete stáhnout zde Win32, Win64 (od Lukáše Bartáka) (návod na přeložení pod Ubuntu nalezený Ondřejem Pluskalem v sekci mex funkce). Pozor: V MATLABu pak používejte funkci gsmo (help k ní získáte pomocí `help gsmo') a nikoli gsmo_mex.
- Je dobré nastavit `options.verb' (viz help), abychom viděli, jak optimalizace postupuje.
- Je dobré také omezit maximální počet iterací nastavením `options.tmax'. Důvodem je to, že když je přímá úloha QP nesplnitelná, je (podle jisté věty o QP dualitě) duální úloha neomezená (viz [2]) - tudíž algoritmus s neomezeným počtem iterací nikdy neskončí.
- Je nutno se dívat na výstupní parametr `stat', podle kterého poznáme, zda optimalizace skončila úspěšně či neúspěšně. Pokud skončila neúspěšně, musíme zjistit proč.
| C = Inf | C = 1 |
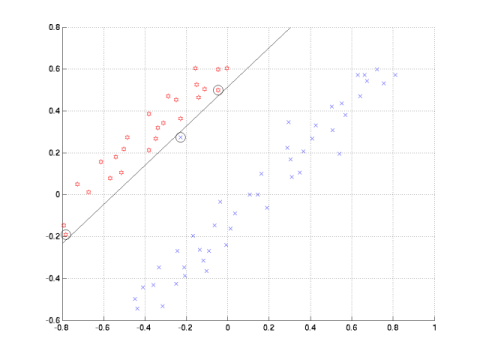 |
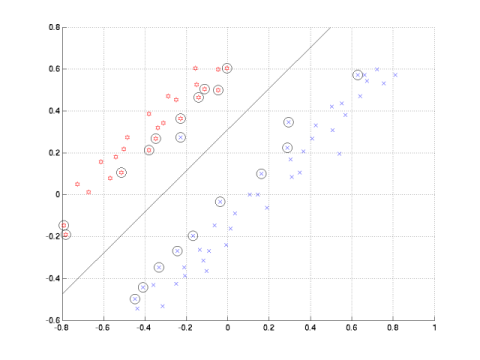 |
x = (součet hodnot
pixelů v levé
polovině obrázku) - (součet
hodnot pixelů v pravé
polovině obrázku)
y = (součet hodnot pixelů v horní polovině obrázku) - (součet hodnot pixelů v dolní polovině obrázku)
y = (součet hodnot pixelů v horní polovině obrázku) - (součet hodnot pixelů v dolní polovině obrázku)