Let
![]() be a training set of
observable vectors
be a training set of
observable vectors
![]() and corresponding binary hidden
states
and corresponding binary hidden
states ![]() . The binary classifier
. The binary classifier
![]() assigns the vector
assigns the vector ![]() to a hidden state
to a hidden state ![]() such that
such that
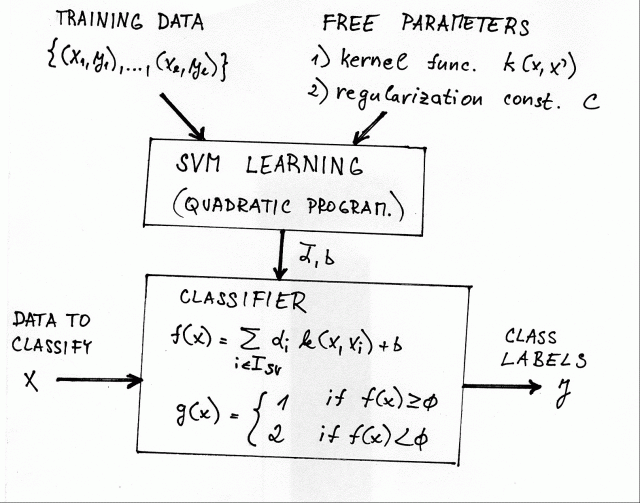
The training stage of the SVM classifier is transformed to a quadratic
programming optimization task. The input of the optimization task is the
training set ![]() , kernel function
, kernel function ![]() and a regularization constant
and a regularization constant
![]() . The output of the optimization is the weight vector
. The output of the optimization is the weight vector ![]() and
the bias
and
the bias ![]() . Thus the SVM training takes care of determination of the
parameters
. Thus the SVM training takes care of determination of the
parameters ![]() ,
, ![]() . The remaining free parameters, i.e. kernel function
. The remaining free parameters, i.e. kernel function
![]() and
the regularization constant
and
the regularization constant ![]() , must be selected based on another principle. A
common practice is to minimize the cross-validation estimate of the
classification error with respect to these free parameters.
, must be selected based on another principle. A
common practice is to minimize the cross-validation estimate of the
classification error with respect to these free parameters.
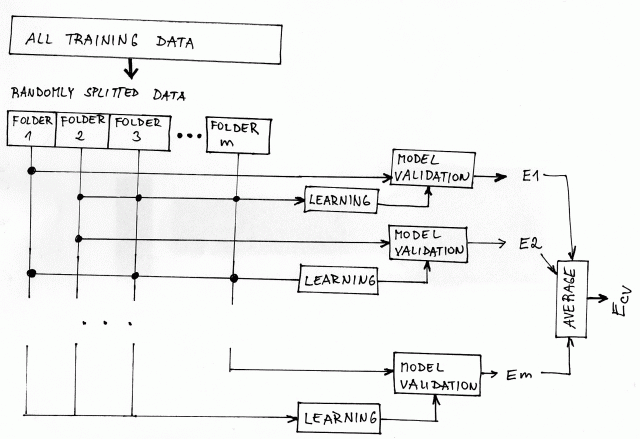
The cross-validation estimate of the classification error is computed as
follows. The training set
![]() is
randomly and uniformly partitioned into
is
randomly and uniformly partitioned into ![]() subsets
subsets
![]() ,
,
![]() such that
such that
![]() . The
computation of the cross-validation error involves:
. The
computation of the cross-validation error involves:
| svm_exp1 | Example on training SVM and using SVM classifier. |
| crossval | Partitions data for cross-validation. |
| svmlight or smo | Training procedures for binary SVM classifiers. |