The Universal Embeddings (UnED) Dataset
The UnED Dataset was made possible by:
Nikolaos-Antonios Ypsilantis,
Kaifeng Chen,
Bingyi Cao,
Mario Lipovsky,
Pelin Dogan-Schonberger,
Grzegorz Makosa,
Boris Bluntschli,
Mojtaba Seyedhosseini,
Ondrej Chum,
Andre Araujo.
What is the Universal Embeddings (UnED) Dataset and benchmark?
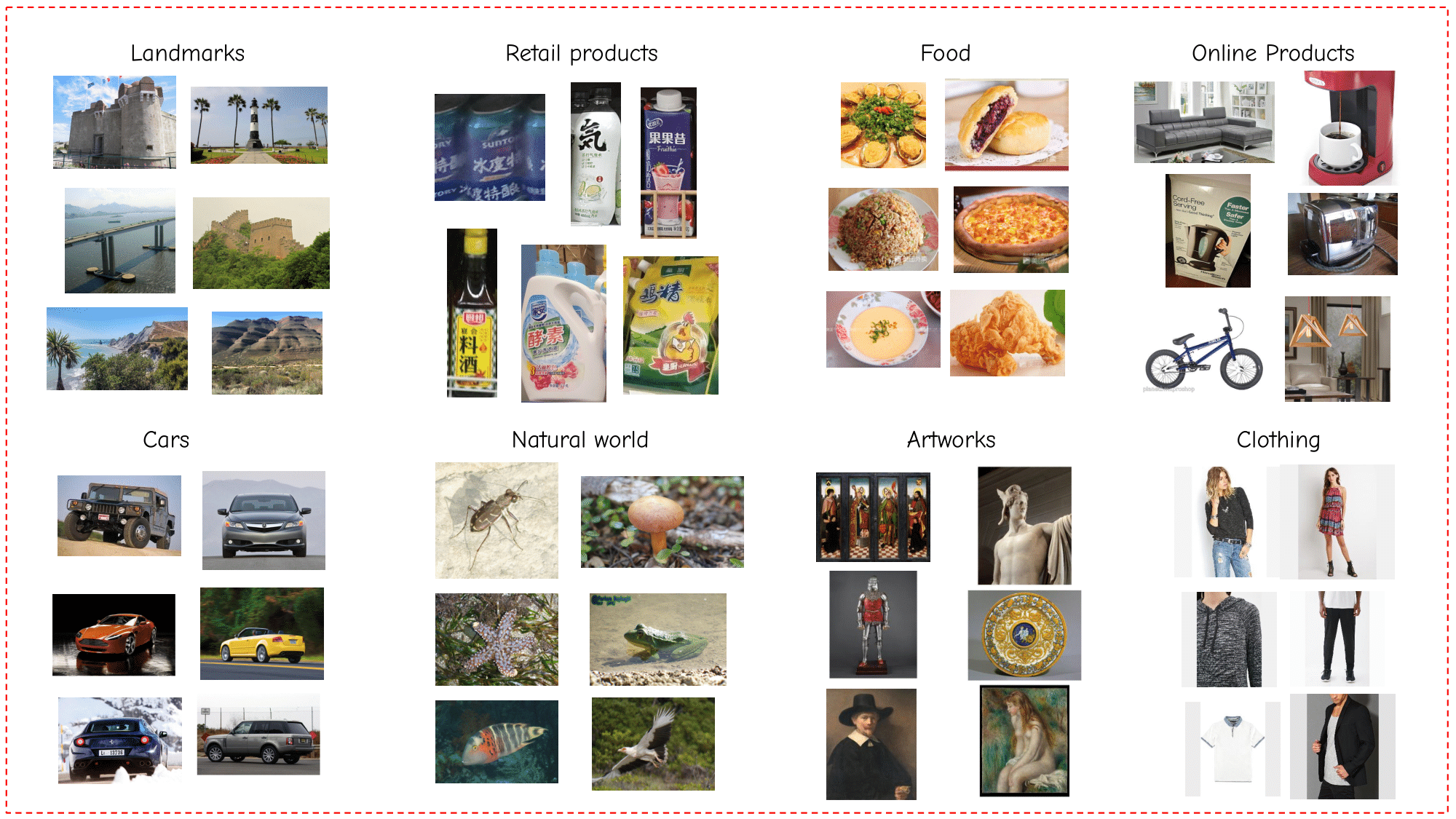
The Universal Embeddings (UnED) Dataset and benchmark consitutes the first large-scale dataset for research on universal image embeddings.- It contains more than 4M images from 349k classes in 8 different visual domains, representing diverse & real use cases: food, cars, online products, clothing, natural world, artworks, landmarks and retail products (see Figure on top of the webpage). We leverage already-existing public datasets to construct UnED, carefully combining them into a common format, with standard splits and metrics.
What is the task of Universal Image Embeddings?
The task of universal image embeddings tests a model's ability to produce representations that work well across the 8 different visual domains, at the same time. It is a direct generalization of the standard single-domain task that has been the main focus of the image embedding and metric learning community for the past years. It consitutes a supervised metric learning task, and we formulate a standard training and testing procedure in order to ensure fair comparisons between proposed methods.Train and Validation sets
Training and validation splits of the UnED dataset are proposed; they consitute of the union of training and validation splits of the visual domains that comprise the UnED dataset. We follow the original splits of the subdomains, however we also propose our splits for the domains that either do not propose specific splits or whose task does not match to the proposed one. These splits consitute the images that a model can see during the training phase. For each subdomain of the validation split of the UnED dataset, we also propose a query and index part of the validation set, in order to perform validation that matches the final evaluation task (on the test set).Test set and final evaluation
The test set of the UnED dataset consists of the union of the test sets of the different visual domains. More specifically, each domain's test set consists of an index and a query set. During the evaluation, all images in the merged query set are matched across the merged index set, and not across their own domain's index set only. Models are tested in the 64-dimensional embedding regime, in order to promote a realistic environment of search given the large scale nature of the task. Performance is measured through two metrics, namely R@1 and mMP@5.Downloads
Pretraining Checkpoints (used to train with our codebase)
Universal Embedding Checkpoints (output of training with our codebase)
Dataset
In order to use the UnED dataset, you first neet to download the images of the different subdomains from the original sources. We provide the direct download links below. If you encounter any problems downloading any of the datasets from their original sources that we have linked, please contact us in order to help you. Then, use the provided ground truth .json files that include the splits of the UnED dataset.
- Original sources of Images:
- Food2k Dataset
- CARS196 Dataset
- SOP Dataset
- InShop Dataset
- iNaturalist 2018
- Met Dataset
- GLDv2 Dataset
- Rp2k Dataset
- Splits of the UnED dataset:
- ground-truth (.json) files (52 MB)