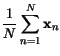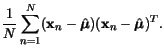Odhad parametrł
Tomį¹ Svoboda
Pųedpoklįdįme, ¾e tvar hustoty rozdģlenķ je znįm 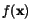 .
Na
zįkladģ pozorovanżch dat se sna¾ķme odhadnout parametry. Podrobnģj¹ķ
odvozenķ mł¾e čtenįų najķt v knize [1] nebo
[2].
.
Na
zįkladģ pozorovanżch dat se sna¾ķme odhadnout parametry. Podrobnģj¹ķ
odvozenķ mł¾e čtenįų najķt v knize [1] nebo
[2].
Uva¾ujme hustotu
zavisķcķ na vektoru parametrł
![$\mbox{\boldmath$\theta$\unboldmath }=[\theta_1, \dots, \theta_M]^T$](img2.gif) .
Pro jednoduchost nynķ zanedbejme označenķ pųķslu¹nosti ke tųķdģ.
Stejnį śvaha platķ pro v¹echny tųķdy. Pro vyjįdųenķ zįvislosti hustoty
na paramtrech, zavedeme podmķnģnou hustotu
.
Pro jednoduchost nynķ zanedbejme označenķ pųķslu¹nosti ke tųķdģ.
Stejnį śvaha platķ pro v¹echny tųķdy. Pro vyjįdųenķ zįvislosti hustoty
na paramtrech, zavedeme podmķnģnou hustotu
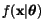 .
Z trénovacķ mno¾iny
mįme
.
Z trénovacķ mno¾iny
mįme 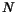 vektorł
vektorł
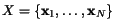 .
Za pųedpokladu, ¾e
tyto vzorky byly vybrįny nįhodnģ, je jejich sdru¾enį hutota rovna
součinu jednotlivżch hustot.
.
Za pųedpokladu, ¾e
tyto vzorky byly vybrįny nįhodnģ, je jejich sdru¾enį hutota rovna
součinu jednotlivżch hustot.
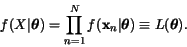 |
(1) |
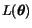 je funkce
je funkce
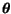 pro dané
pro dané 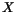 ,
nazżvįme ji vģrohodnost parametrł. Čili maximįlnģ vģrohodnż odhad parametrł
bude takovż, jen¾ maximalizuje hodnotu vģrohodnosti, rovnice
(1) V praxi je mnohem snaz¹ķ minimalizovat funkci
,
nazżvįme ji vģrohodnost parametrł. Čili maximįlnģ vģrohodnż odhad parametrł
bude takovż, jen¾ maximalizuje hodnotu vģrohodnosti, rovnice
(1) V praxi je mnohem snaz¹ķ minimalizovat funkci
Pro normįlnķ rozdģlenķ mł¾eme odvodit nejvģrohodnģj¹ķ odhad stųednķ
hodnoty a kovariančnķ matice
- 1
-
Christopher M. Bishop.
Neutral Networks for Pattern Recognition.
Clarendon Press, Oxford, Great Britain, 3th edition, 1997.
- 2
-
Athanasios Papoulis.
Probability and Statistics.
Prentice-Hall, 1990.
Tomas Svoboda
2000-03-23