License Plate Recognition and Super-resolution from Low-Resolution Videos
We developed learnable end-to-end CNN architecture (LprNet) for license plate recognition from low-resolution videos. The CNN is fed with a sequence of low-resolution images obtained by tracking a LP on a car. The LprNet outputs a distribution over strings with variable number of characters (hence it can be used in variable countries with different LP layout).
In parallel we developed a CNN generating high-resolution LP images from low-resolution ones. The generated high-resolution image i) preserves structure (like pose, lighting, background etc) of the low-res input and ii) it depicts the string which was previously recognized from a sequence.

Results
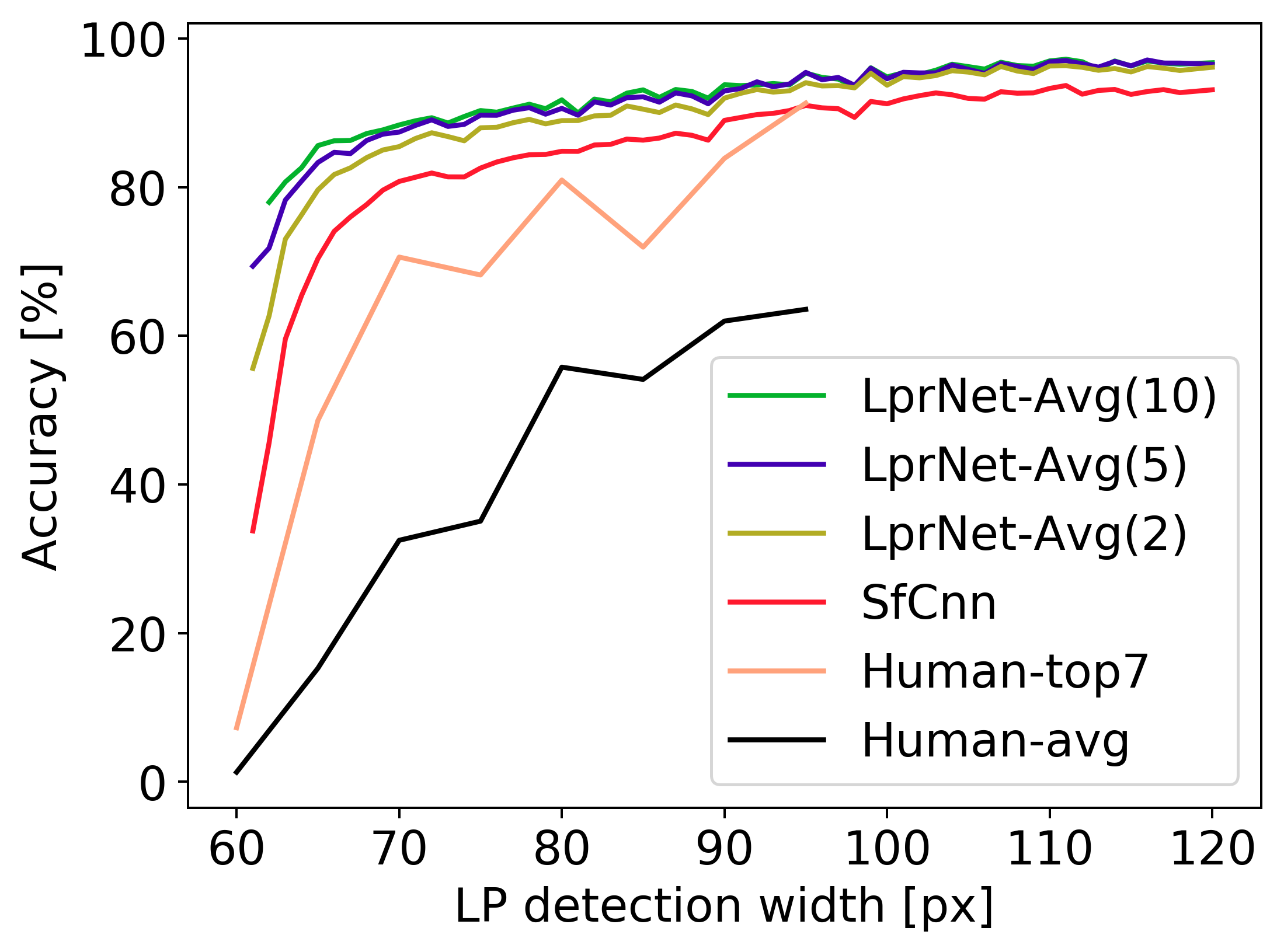
The classification accuracy of LprNet significantly surpasses humans. The figure below shows the test classification accuracy w.r.t. horizontal resolution of the LP image for i) average human (Human-avg), ii) best result of 7 independent humans (Human-top7), iii) CNN using a single frame (SfCNN) and iv) LprNet using video sequence with 2, 5 and 10 frames.
It is seen that 60 pixels wide LP images are not recognizable by humans (accuracy < 3%) while LprCnn using video with 10 frames achieves almost 80% accuracy.
Example videos
Examples of generated super-resolution images
The first column shows the input low-res image with ground-truth string (red). The second and the third columns show generated high-res images depicting the most probable and the 2nd most probable strings recognized by the LprNet from a video (here we show only the 1st frame in the 1st column).